CVPR 2025 | ECBench:统一静态、动态与幻觉场景的机器人认知评测体系

项目简介
尽管已有方法如客户端正则化(FedProx、SCAFFOLD)、服务器聚合优化(FedOPT、FedDF)和数据增强策略(FedMix、FedFA)在缓解数据异质性方面取得了一定进展,但它们大多依赖局部信息或过于理想的分布假设,难以在复杂非IID场景中稳定泛化。
在厨房里,一个配备GPT-4o的机器人能流利解释菜谱,却对“灶台左侧第三个抽屉里是否有备用刀具”这样的空间推理问题束手无策;在动态办公场景中,它虽然能识别投影仪开关状态,却无法执行“将屏幕恢复到十分钟前会议初始界面”这类时空回溯指令。这些看似简单的任务,暴露了当前大型视觉语言模型(LVLMs)在物理世界认知中的根本缺陷。
通过对OpenEQA、ScanQA等主流评测基准的深度分析,研究团队揭示了四大认知壁垒(表1):
系统断层:现有测试如同散落拼图,缺乏从低到高的层级化评估体系。 自我意识缺失:当前所有的主流测试问题均采用第三人称视角,忽视以机器人本体为中心的空间定位等核心需求。 动态盲区:90%的现有数据集基于静态场景假设,无法检验时空连续体中的认知连贯性。 三维幻觉:在反常识场景中(如牙刷出现在灶台旁),主流模型错误率高达90%。

表1:ECBench相比主流评测基准的优势
ECBench:打开具身认知的「三维罗盘」
2.1 三大认知维度重构评测体系
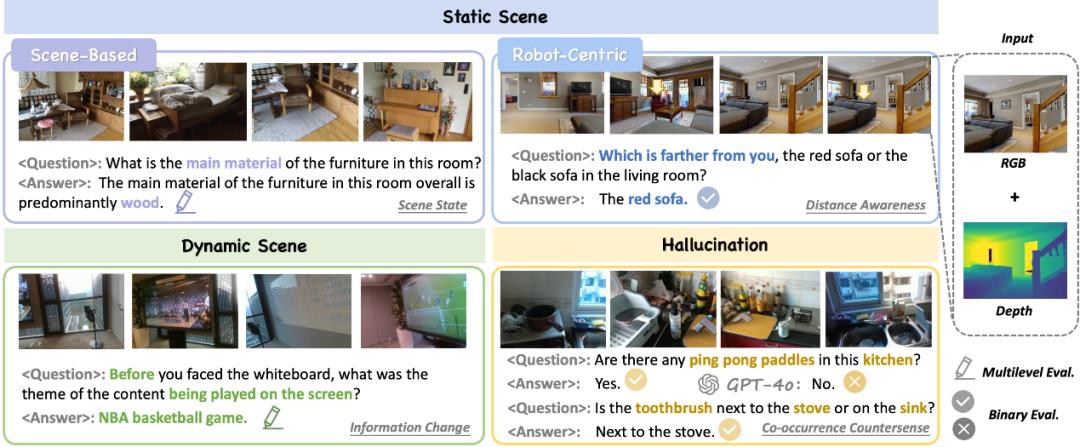
ECBench构建了覆盖静态场景-动态场景-幻觉场景的立体评估框架,其特点体现在:
静态场景:
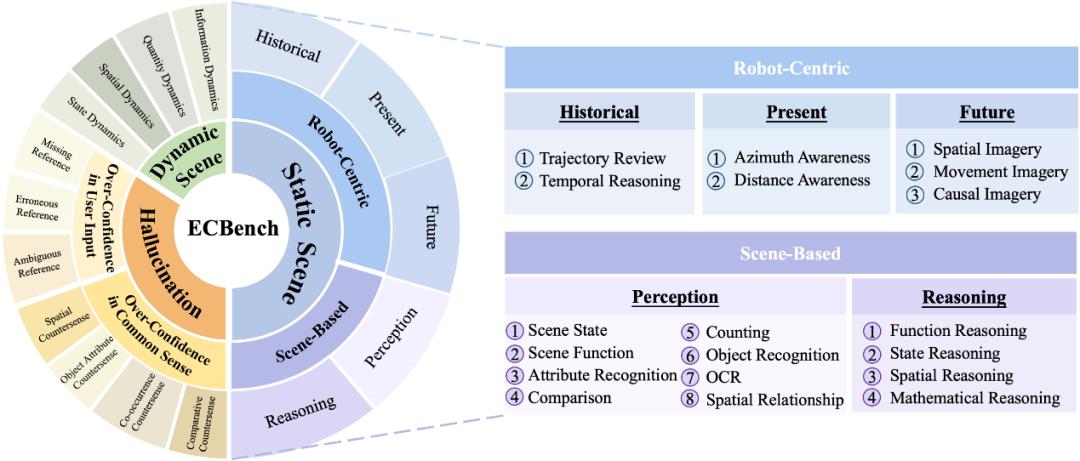
提出以机器人为中心认知测试集,包含轨迹回溯、本体定位等19项能力; 引入“历史-当下-未来”三维时空评价体系,并要求模型理解自身行动对环境的影响。
动态场景:
设计了空间动态、信息动态、数量动态、状态动态四类开放世界任务。
幻觉场景:
划分常识过度依赖与指令过度信任两大风险类别; 设置四类反直觉场景,充分考验视觉语言模型尊重物理现实的能力。
为了保证问答数据的准确性与全面性,此团队采用全手工标注的方法,且标注人员全部是具身智能与计算机视觉领域的研究专家。ECBench包含30种认知能力,如果使用传统的逐视频标注方法,会导致严重的类别失衡。因此,此团队采用了逐类别标注方式,确保了普通能力与稀有能力问答对数量的平衡。
GPT-4o压力测试:让模型在「盲测」状态下连续六轮回答所有问题,暴露那些仅凭常识就能破解的题目; 人工语义手术:对通过率超过83%的问题进行针对性改造,注入必须依赖视觉线索的关键细节; 三重迭代验证:经过三轮筛选优化后,最终通过交叉验证确保每个QA对的视觉依赖性。
这套方法论如同为数据集安装上"视觉过滤器",使常识性问题的占比从初版的37%降至9.2%。正如团队在论文中揭示的:"当我们用AI最擅长的武器来攻克AI自身的弱点,得到的不仅是更纯净的数据,更是打开视觉认知黑箱的解码器。"最终成型的4324组QA对,从静态环境理解到动态场景追踪,全方位检测语言模型的具身智能水平。
1、视频数据构成:多源融合的视觉库
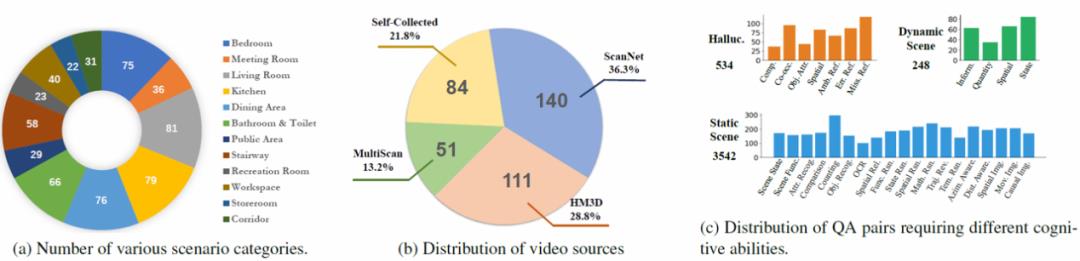
ECBench数据集整合386段RGBD室内场景视频,包含三大来源:
真实场景数据:191段精选自ScanNet(140段)与MultiScan(51段)的高信息密度场景,覆盖厨房操作、楼梯间等复杂空间; 虚拟环境数据:111段HM3D虚拟环境中的第一视角任务记录,包含49段问答智能体探索视频与62段目标导航路径数据; 特殊场景库:84段自主采集视频,包括44个反常识场景(如牙刷放置在灶台旁)和40个动态场景(如实时变化的电子屏幕)。
这些视频涵盖12类室内环境类型,除常见居住空间外,特别纳入娱乐室、设备间等低频场景,构建起多维度环境适应力测试平台。
2、问答体系设计:系统性能力评估框架
数据集核心包含4,324组结构化问答对,实现三大技术创新:
问题复杂度提升:平均问题长度达16.88词,专业词汇量扩展至4,513个,较OpenEQA提升2.6倍语义复杂度; 评估维度拓展:新增534组幻觉场景测试与248组动态场景任务,建立时空连续性评估标准; 系统化架构:通过19项静态能力、4类动态维度、7种幻觉类型的评估矩阵,形成层次化认知评估体系。
实验验证:揭示视觉语言模型的具身认知边界
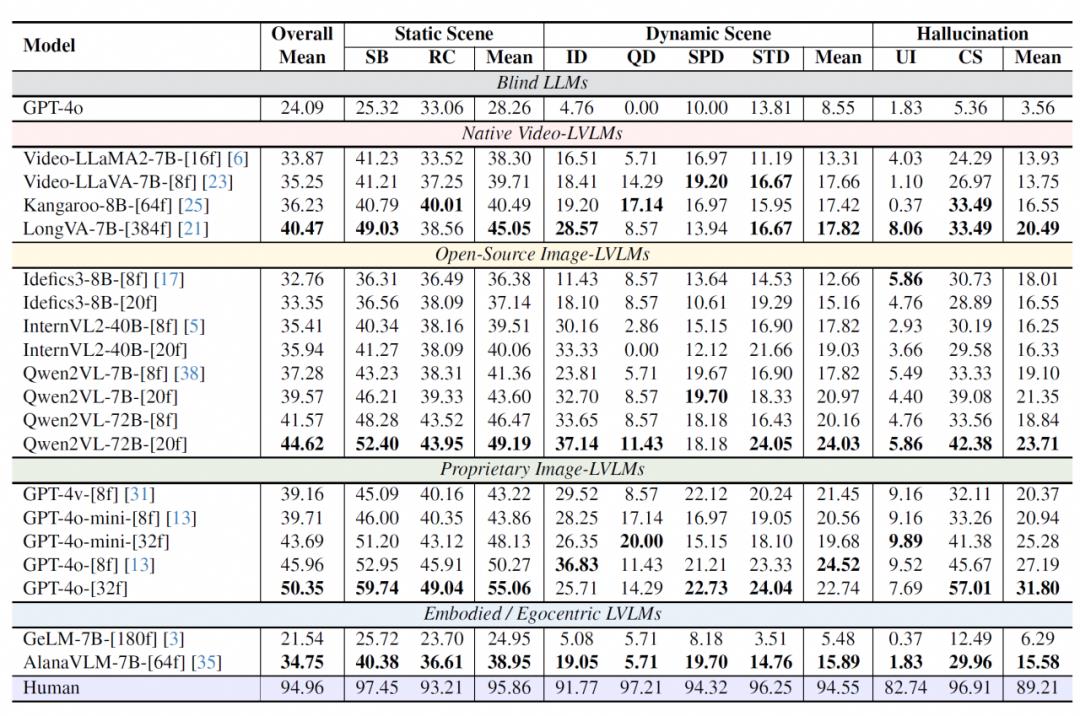
核心模型表现
基于ECBench基准,研究团队对8类主流视觉语言模型(LVLMs)进行系统评测:
闭源模型优势显著:GPT-4o以50.35分领跑,相较开源多模态模型(Qwen2VL-72B)提升12.8%,较开源视频模型(LongVA)提升24.4%; 动态场景普遍薄弱:所有模型在动态场景得分均低于24.52,其中数量动态任务表现最差(InternVL2-40B出现零分案例); 专业模型未达预期:专为具身场景设计的AlanaVLM和GeLM分别仅获34.75和21.54分,暴露领域适应性缺陷。
评估方法创新
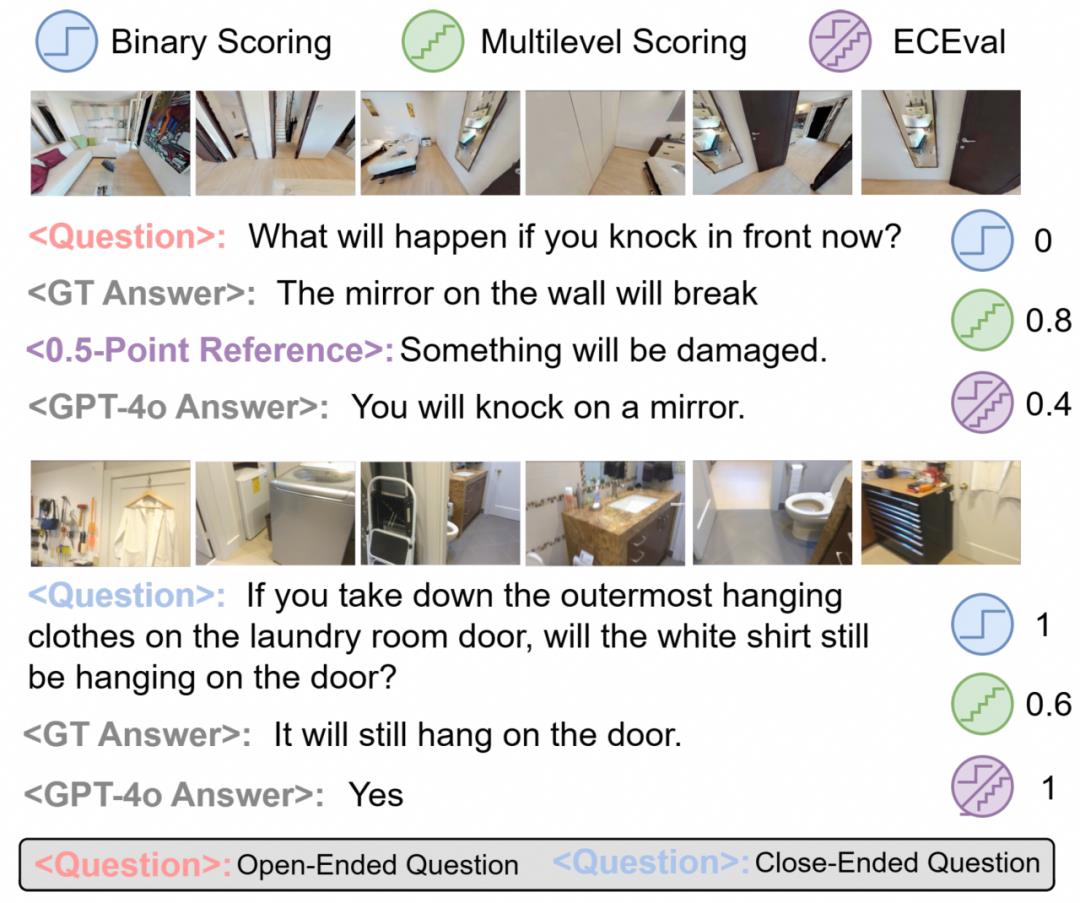
ECEval混合评估框架展现独特优势:
开放性问题采用0.5分参考答案引导的多级评分,使GPT-4o评分偏差降低30%; 封闭性问题使用二元判定,避免语义一致但表述差异导致的误判; 综合评估准确率较传统方法提升17.3%,特别是在动态场景评估中差异显著。
上述实验结果证实,现有视觉语言模型在时空连续性理解、自我意识构建、幻觉场景识别等方面仍存在系统性缺陷,为下一代具身智能模型的架构设计指明突破方向。
总结:构建具身智能三维评测体系
ECBench作为融合静态场景、动态场景与幻觉检测的具身认知评测体系,通过30项精细认知任务构建起具身智能的「能力坐标轴」。
实验揭示:当前主流模型在机器人为中心的感知、动态场景理解以及反直觉信息识别等核心场景存在系统性缺陷。研究团队同步研发的ECEval混合评估框架,将开放性问题判准率提升17.3%,建立可信评测标准。这项工作希望能绘制出现有技术的认知边界,为具身智能迈向复杂物理世界提供导航图——当机器开始理解自身与环境的时空关系,真正意义上的智能体革命即将到来。