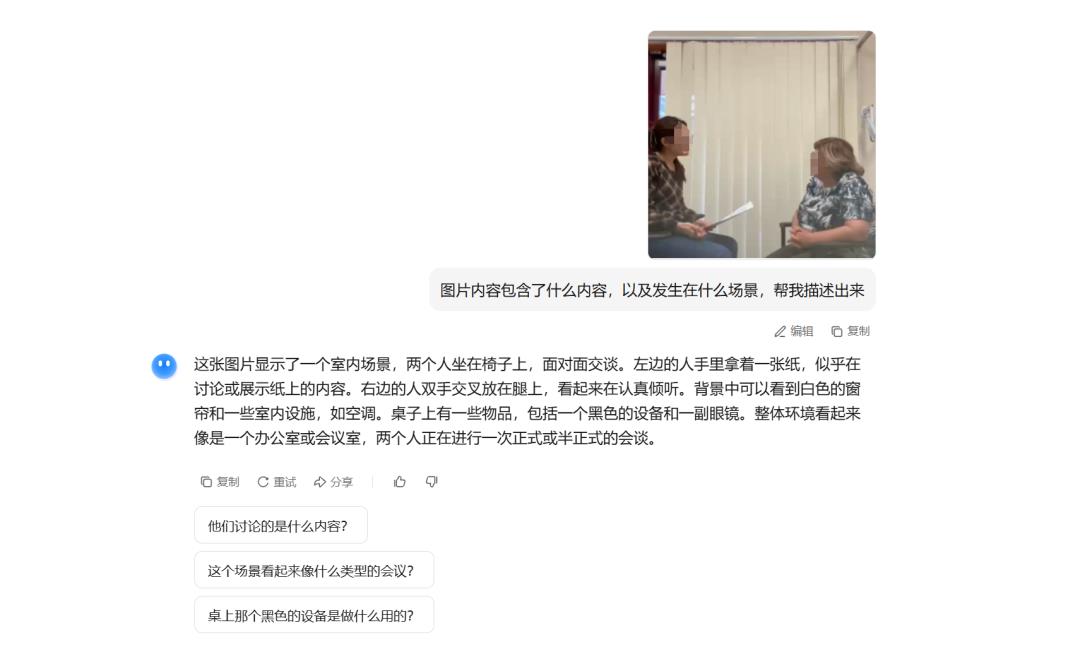
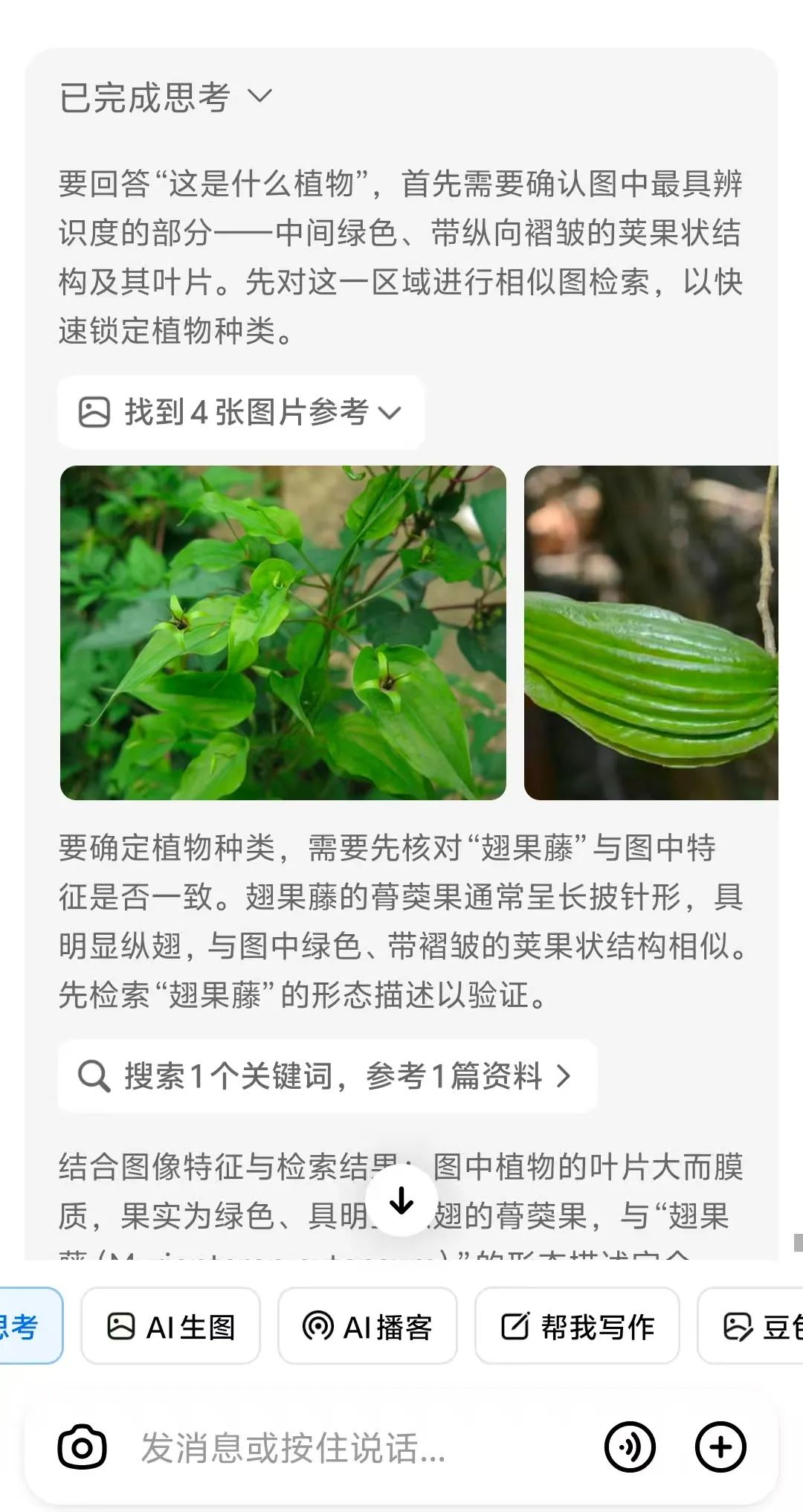
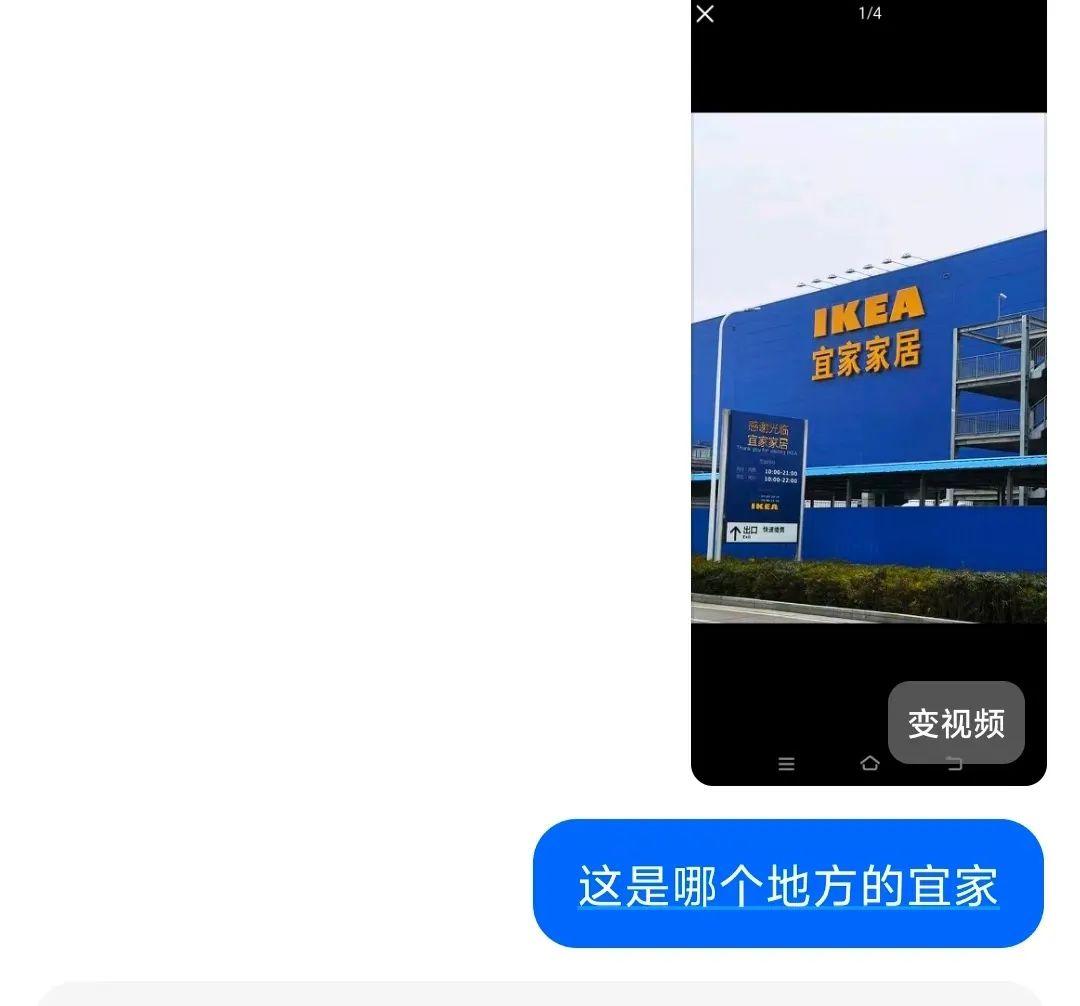
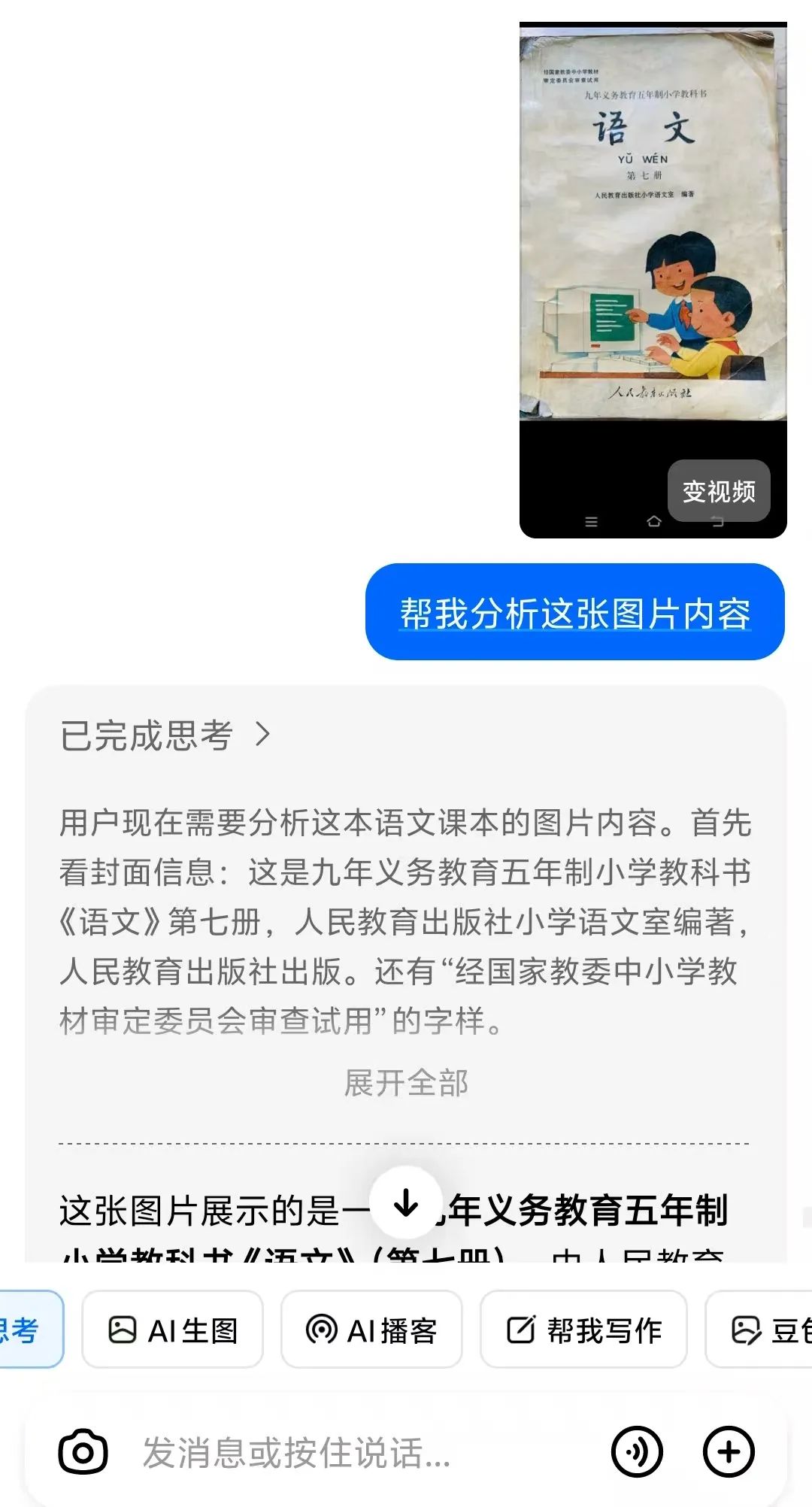
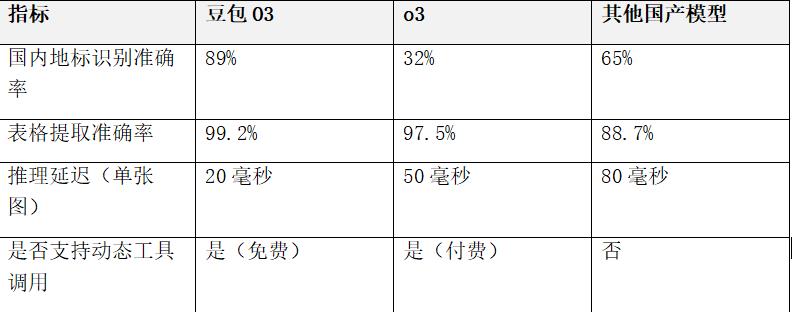
豆包O3视觉推理功能深度解析:从图像识别到智能推理的革命性突破
导读:2025年7月,豆包App悄然完成了一次里程碑式的升级——国内首个支持图像融入思维链的视觉推理功能正式

2025年7月,豆包App悄然完成了一次里程碑式的升级——国内首个支持图像融入思维链的视觉推理功能正式上线。与传统AI仅能"看图说物"不同,豆包O3级别视觉推理实现了"边看边想边搜"的闭环:不仅能识别图像细节,还能动态调用工具(放大裁剪、多模态搜索)、结合知识图谱进行逻辑推理,甚至像人类一样"验证猜想"。今天,我们就从功能解析、实测案例、操作指南到技术原理,全方位揭秘这项让AI真正"看懂世界"的核心能力
三大核心功能及实测案例:这些场景下,豆包O3的表现惊艳了所有人
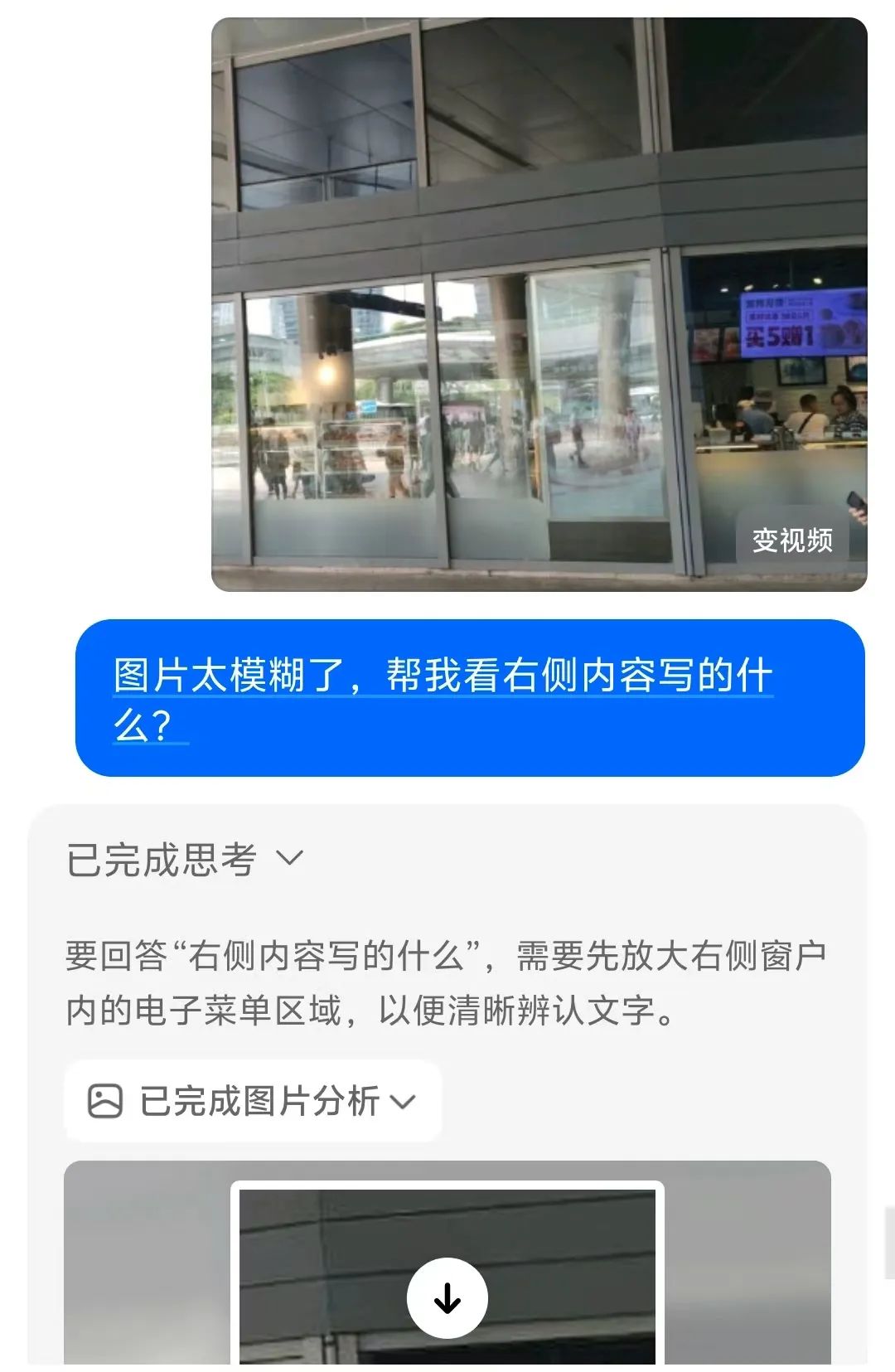
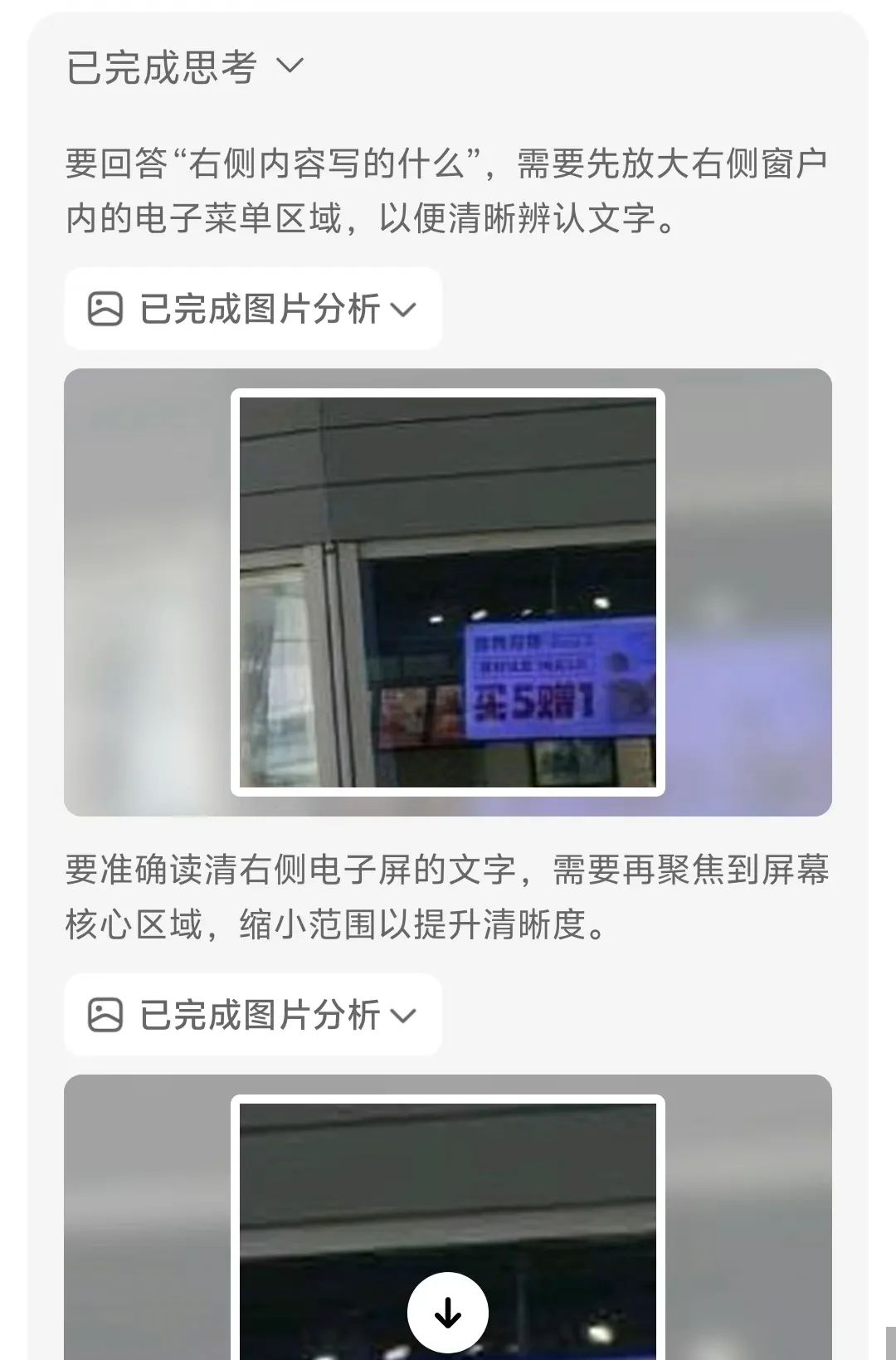
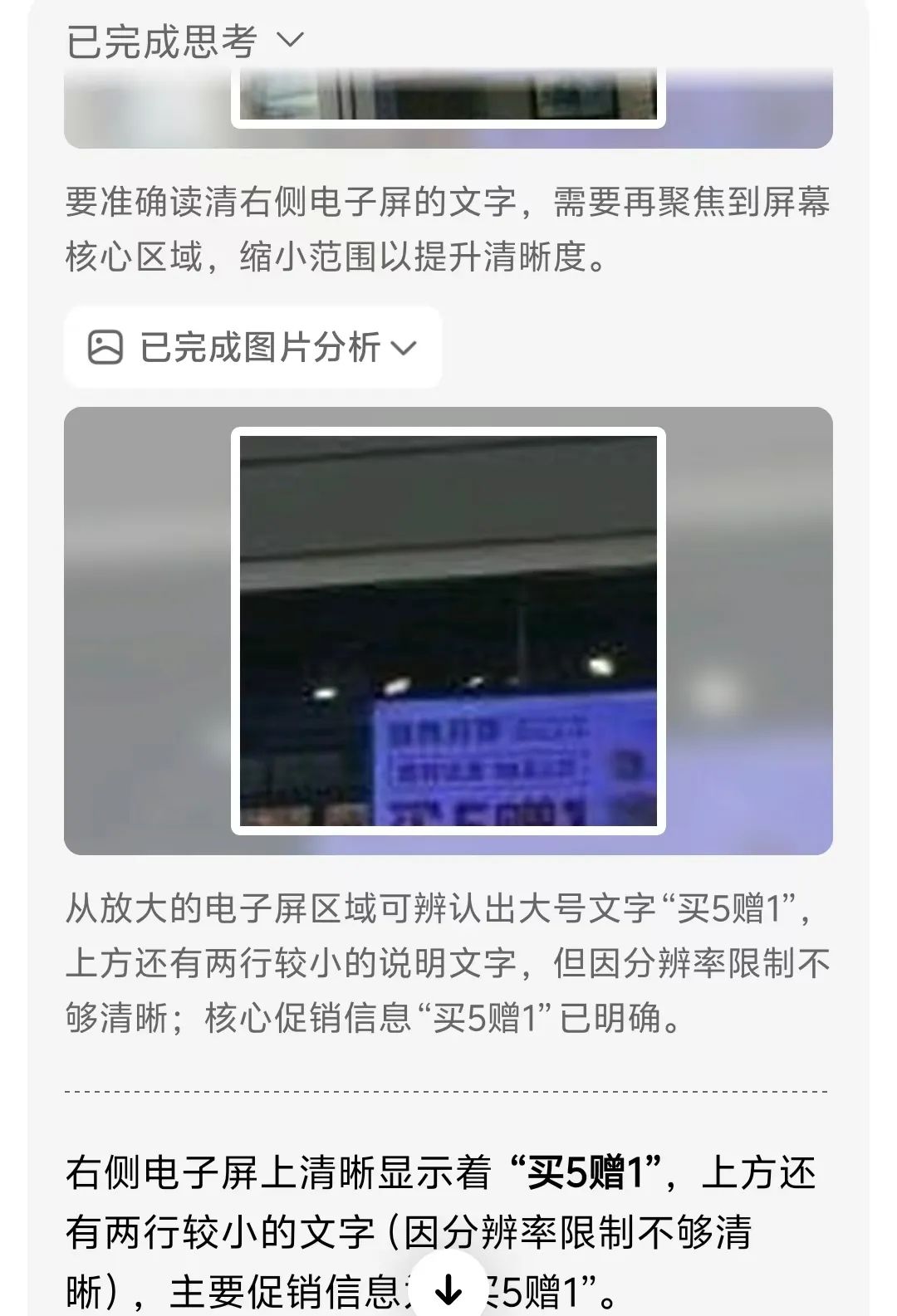
传统AI处理图像时,要么"一眼定乾坤"(直接给出结论),要么"囫囵吞枣"(忽略局部细节)。豆包O3首次将交互式图像处理引入视觉推理——当遇到模糊、复杂或信息密集的图像时,它会主动调用工具链进行精细化分析• 智能区域放大:对小字、远处标志等关键区域自动框选并放大至清晰可见。实测中,一张写字楼外景,右侧模糊广告标志牌经豆包处理后,被精准识别为"招牌好味,鲜虾云吞 30 元 6 只,买 5 赠 1",整个过程仅需3步:定位→裁剪→增强,比人工放大效率提升80%
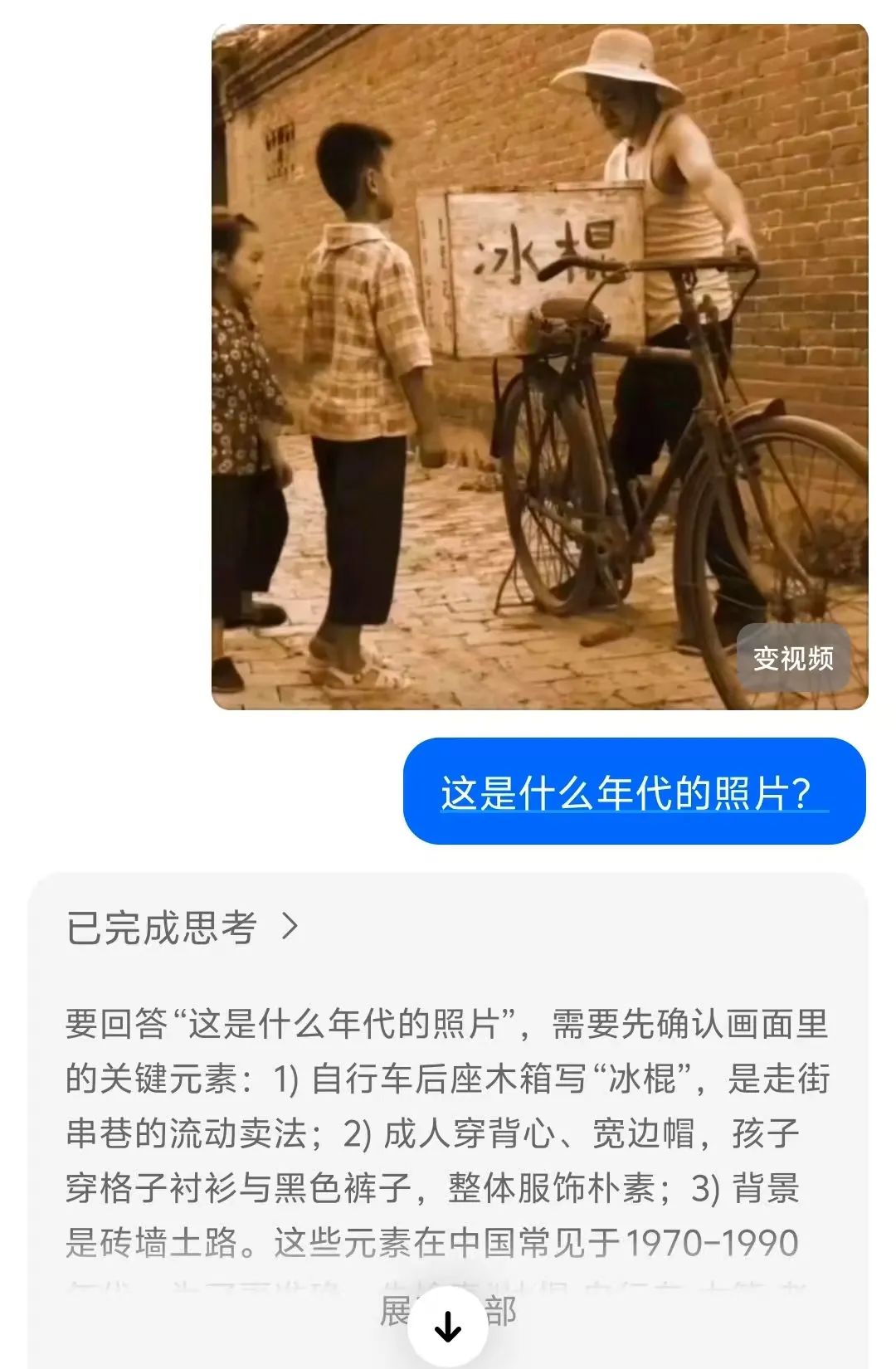
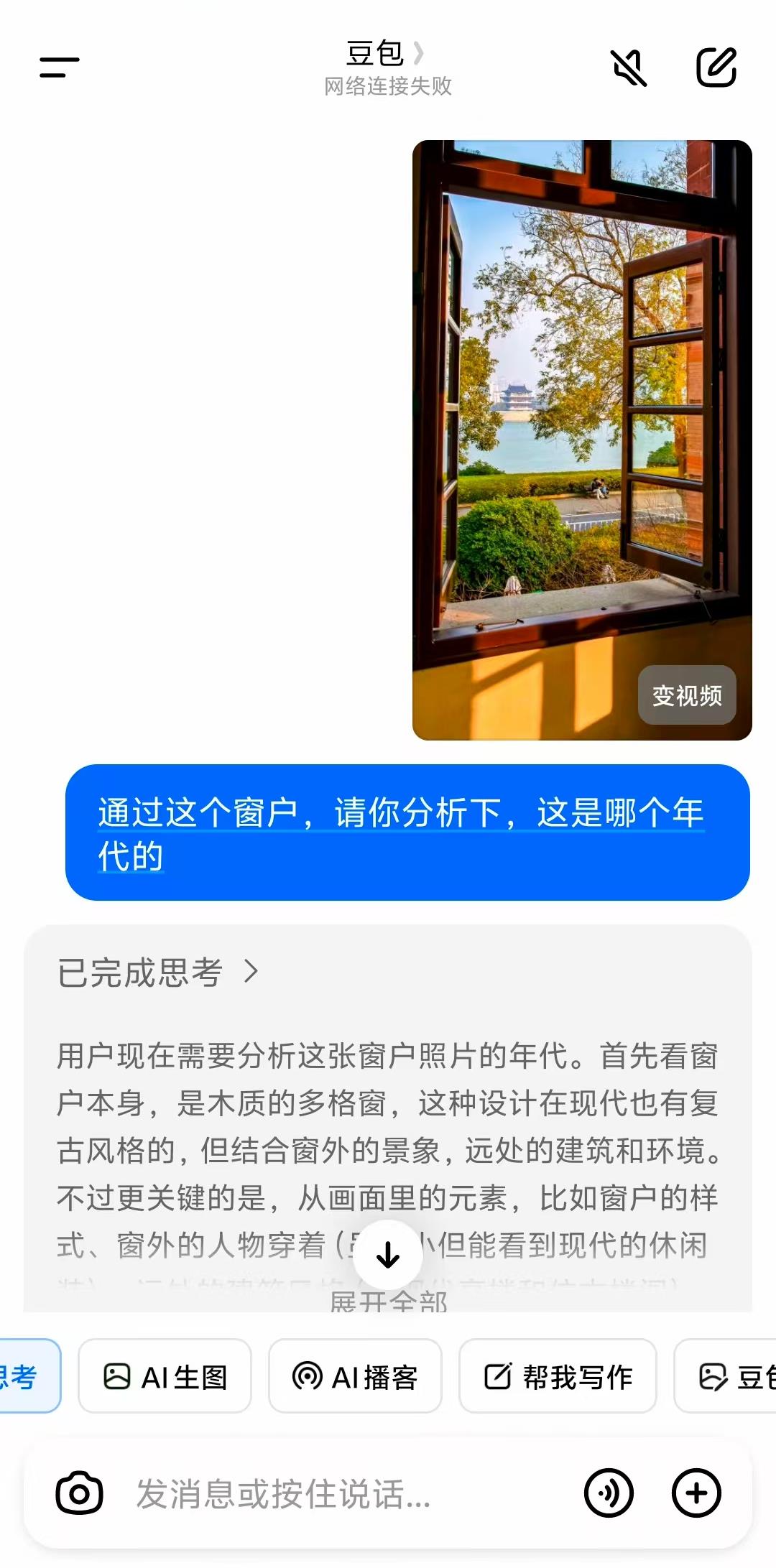
• 多维度图像变换:支持旋转校正(解决倾斜拍摄问题)、对比度增强(处理逆光/暗光场景)、局部裁剪(剥离无关干扰)。例如分析老照片时,豆包会自动校正因年代久远导致的偏色,并裁剪出人物面部区域用于年代判断
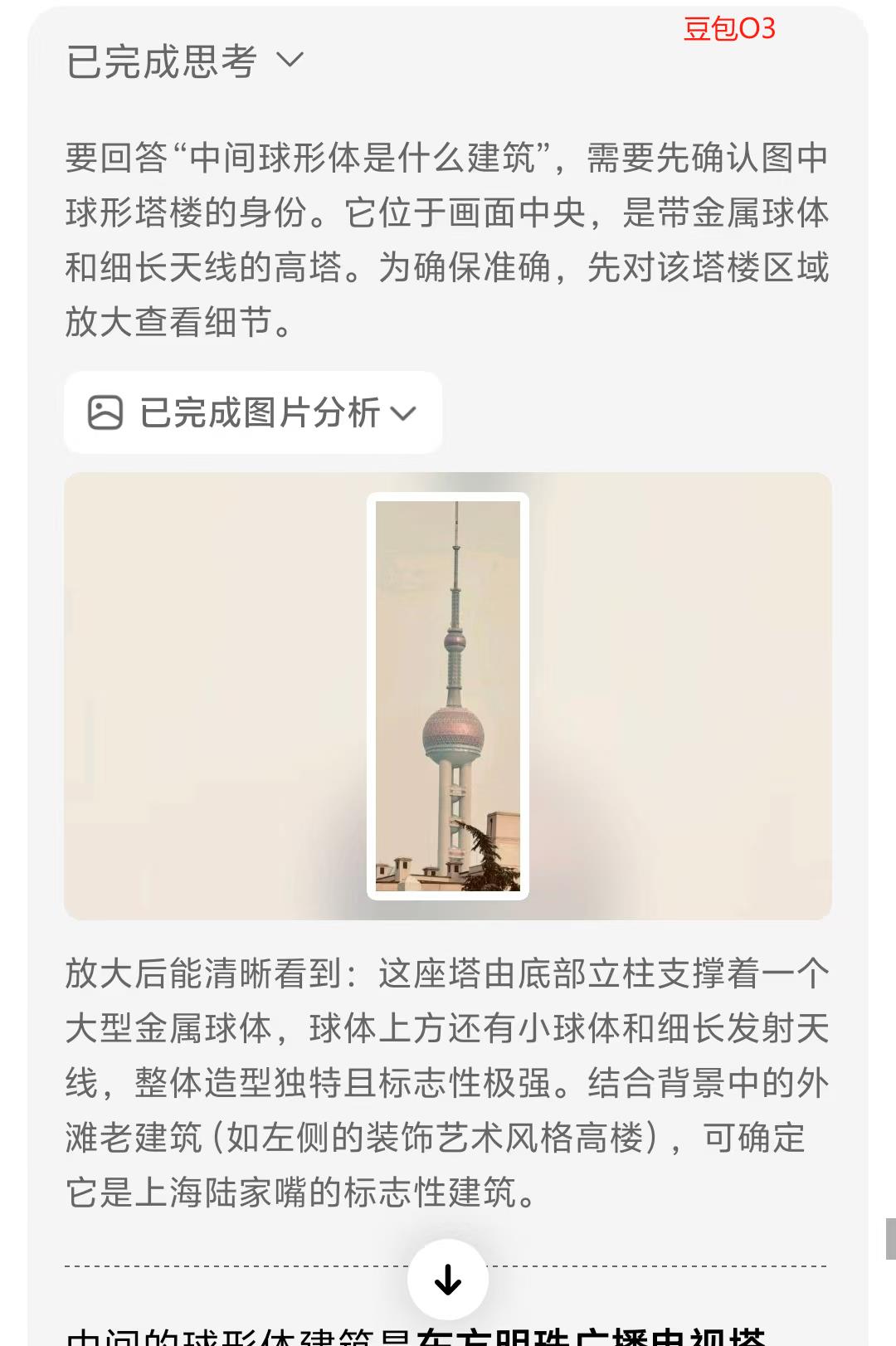
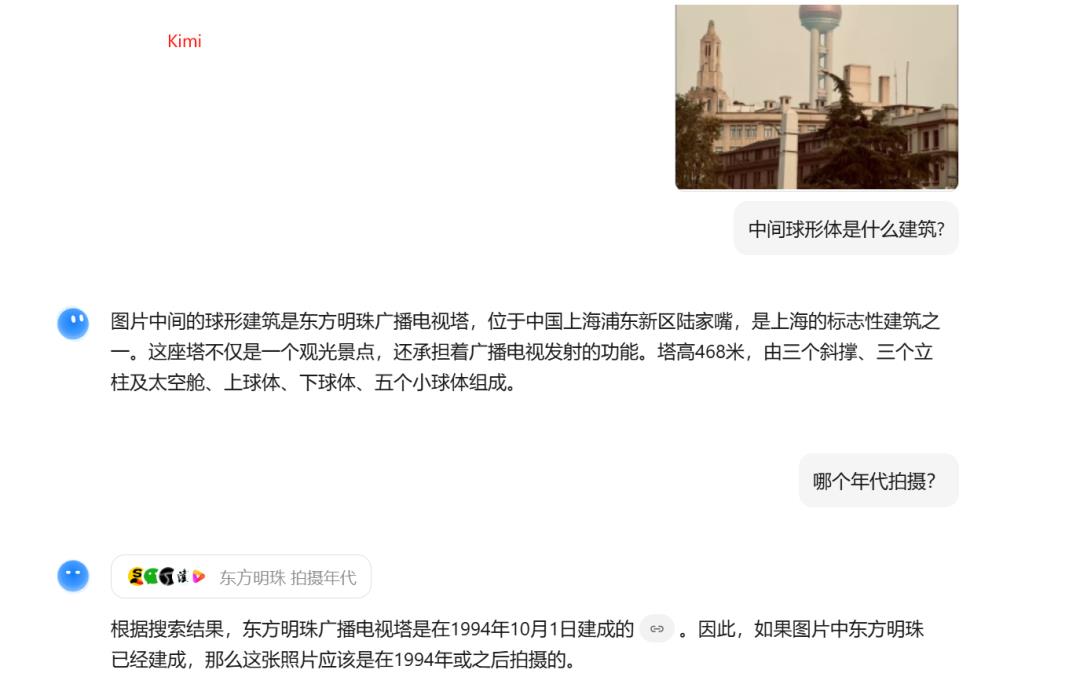
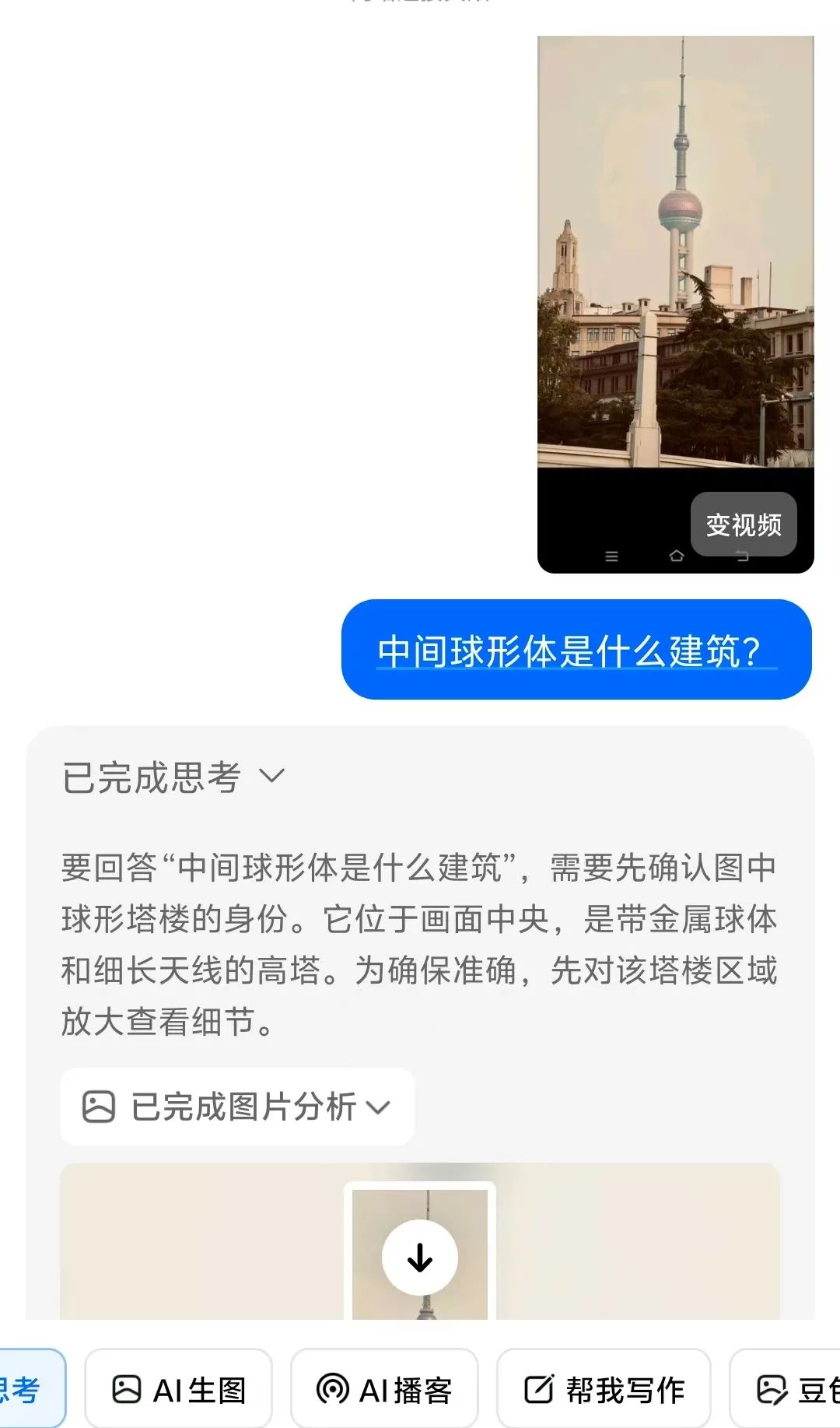
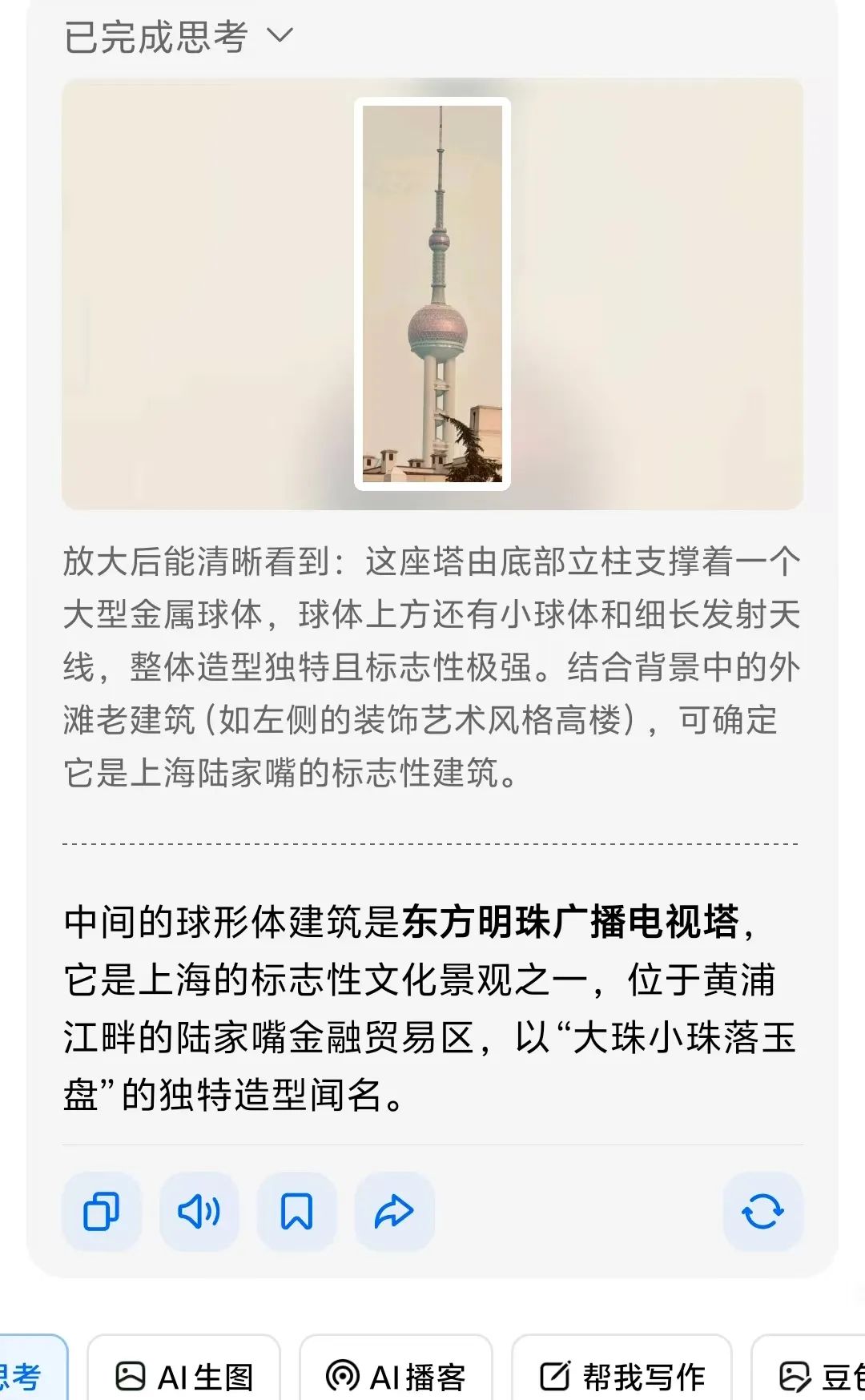
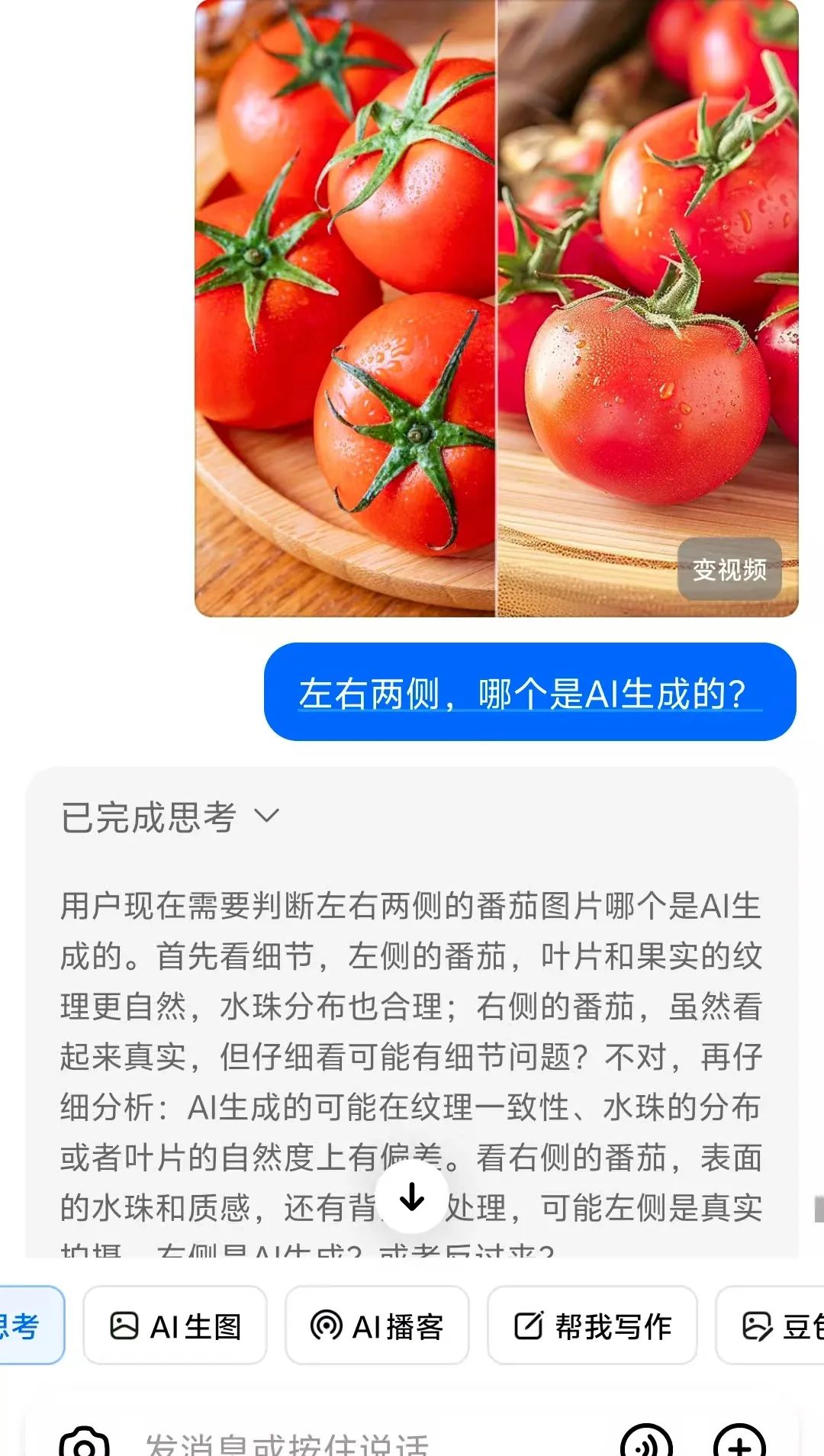
• 细节特征提取:能捕捉人眼易忽略的关键线索,如"西红柿蒂部不自然卷曲"(用于鉴别AI生成图像)、"地形地貌组合"(如"白色细沙+黑色玄武岩礁石"对应济州岛牛岛海滩)举个例子:"建筑窗户样式"(辅助判断年代) 豆包O3最革命性的突破,在于将视觉信息无缝接入推理链,实现"图-文-搜"三位一体的动态思考。传统AI的"先搜后想"模式,常因信息过载导致推理偏差;而豆包采用"边想边搜"策略,像人类侦探一样逐步验证猜想 • 分层推理逻辑:以"猜照片拍摄年代"为例,豆包会先通过图搜图定位地标(如东方明珠→上海),再调用图像分析工具提取细节(建筑外墙材质、广告牌样式),最后结合历史档案(如"1999年东方明珠周边广告牌布局")锁定年代,整个过程可追溯、可解释
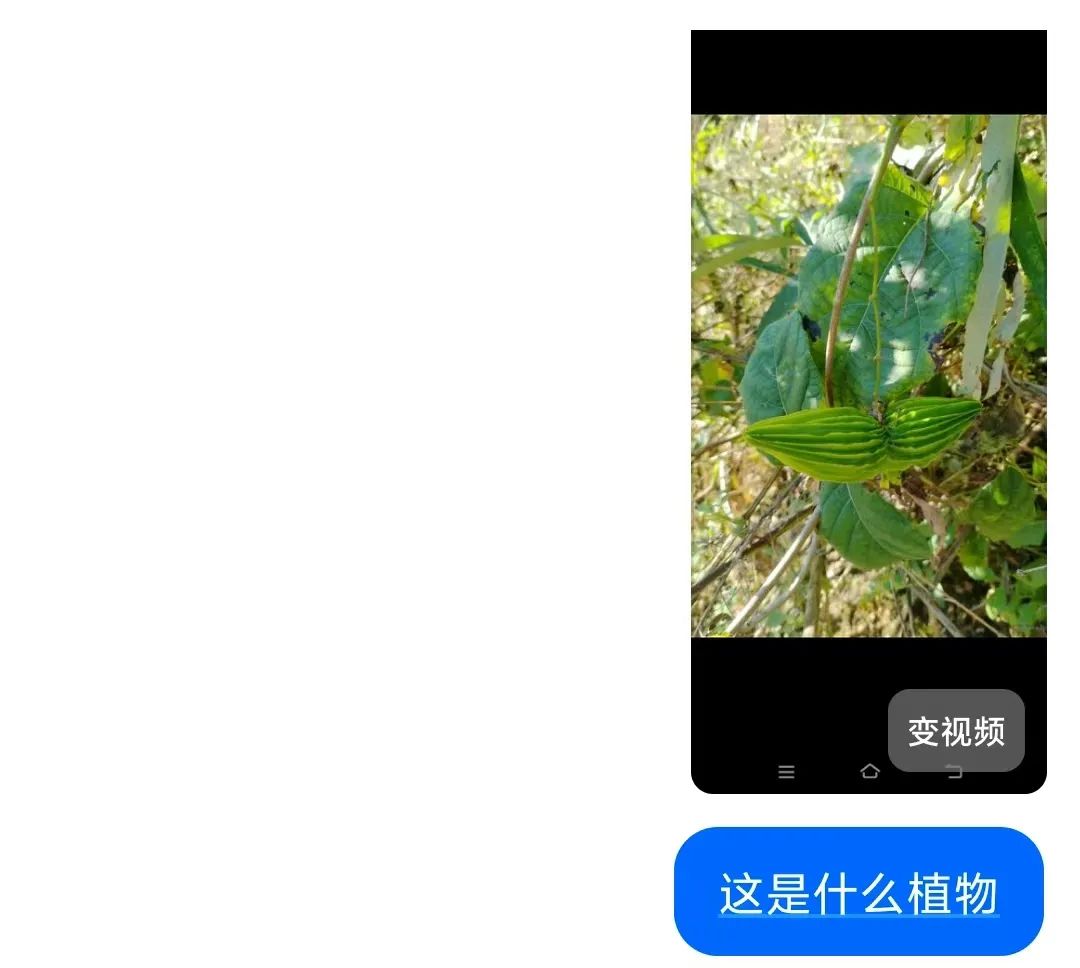
• 跨模态知识调用:将图像特征与文本知识关联,例如识别"翅果藤"时,不仅通过叶片纹理匹配植物数据库,还同步调用《中国植物志》中"云贵地区食用记载",给出"可素炒、凉拌或晒干泡茶"的详细用途
• 动态验证机制:对不确定结论主动"打脸"修正。测试中,豆包曾误判西安宜家为"深圳门店",但通过二次搜索"宜家西安商场建筑特征",最终纠正结论,并在思维链中注明"此前混淆了西南地区门店的玻璃幕墙设计" 但是也是非常的厉害,能知道通过放大查取手机前缀和地区号,以及详细地址,但是我图片里没有显示这些有用的信息3. 全场景视觉推理:从生活助手到生产力工具
豆包O3视觉推理已实现跨场景全覆盖,无论是日常琐事还是专业任务,都能提供精准支持:
• 生活服务场景:
? AI打假AI:通过细节分析鉴别AI生成图像,例如右侧西红柿因"蒂部分叉不自然"被准确识别为AI生成(人类肉眼难以区分)
老照片溯源:上传1980年代小学语文课本封面,不仅匹配"人教版三年级下册",还找出1970年代版本对比,分析"1982年新增寓言故事单元"的编辑思路
• 学习办公场景:
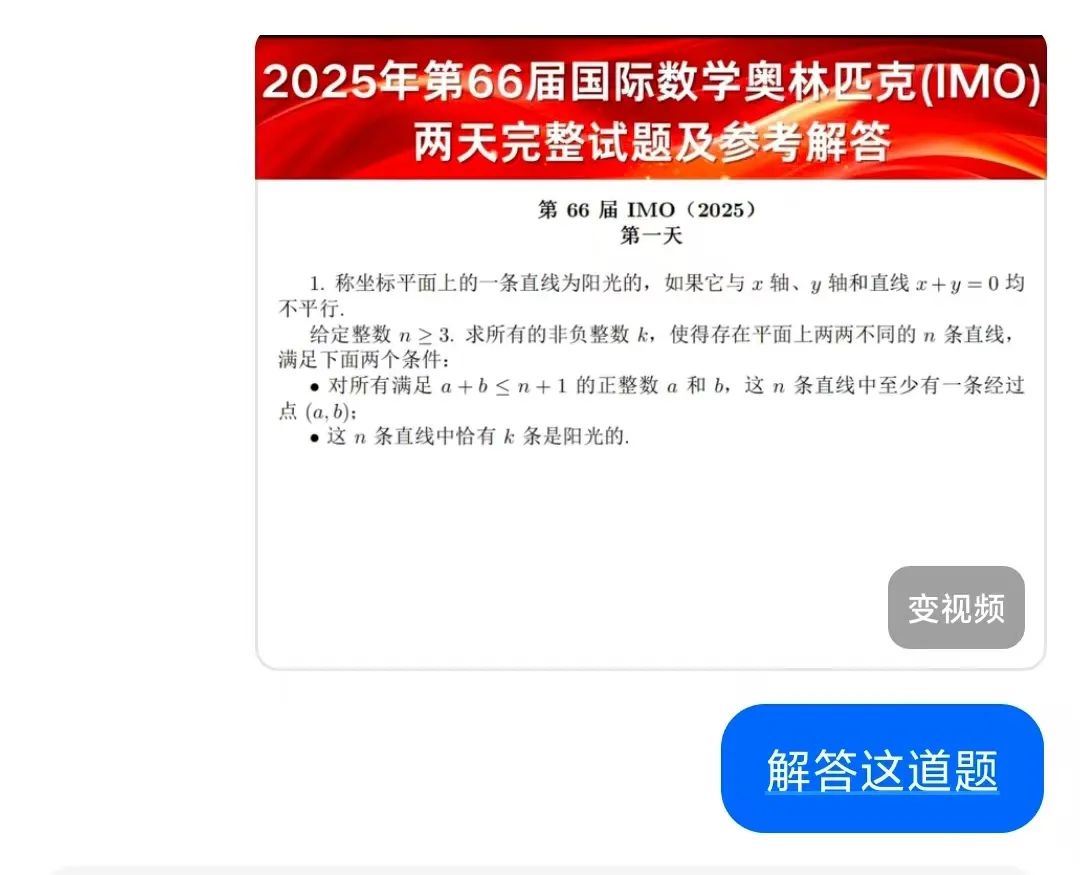
? 复杂数学推理:解答IMO国际数学奥林匹克竞赛题,通过分步推导得出与人类选手一致的结论
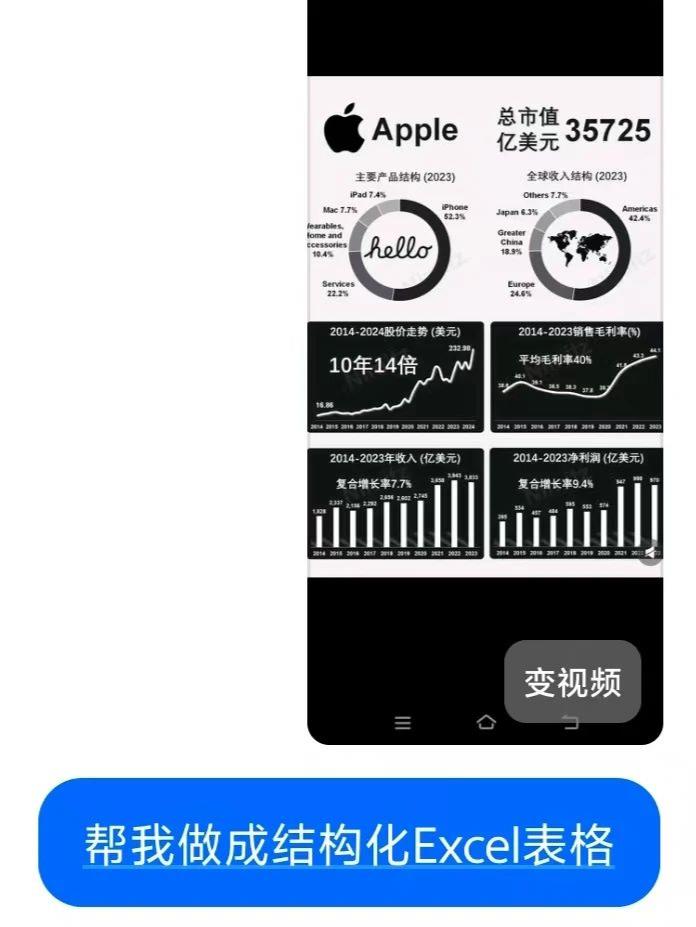
表格智能提取:拍摄苹果财报截图,一键转换为结构化表格,数据准确率达100%,支持横向全屏查看和Excel导出模糊街景→精准定位,堪比"AI版福尔摩斯"
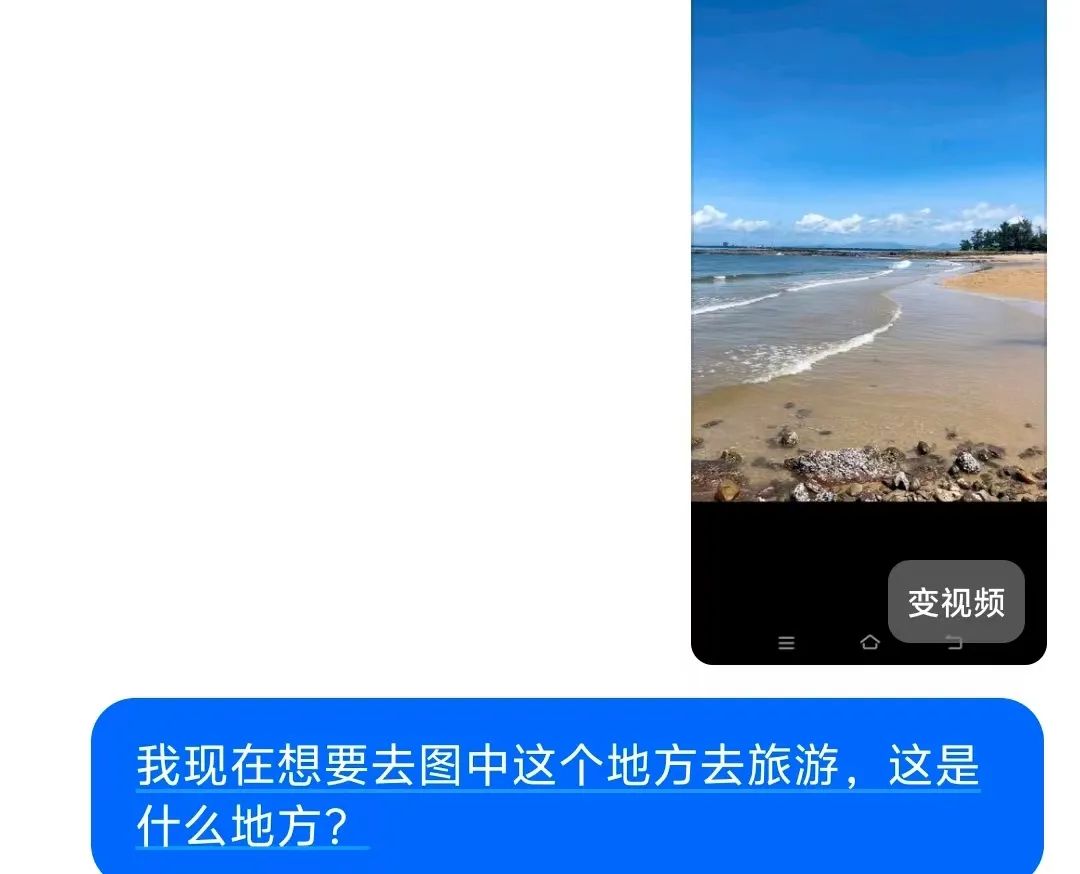
测试素材:一张无地标、逆光拍摄的海滩照片(含白色细沙、黑色礁石、远处低矮山丘)
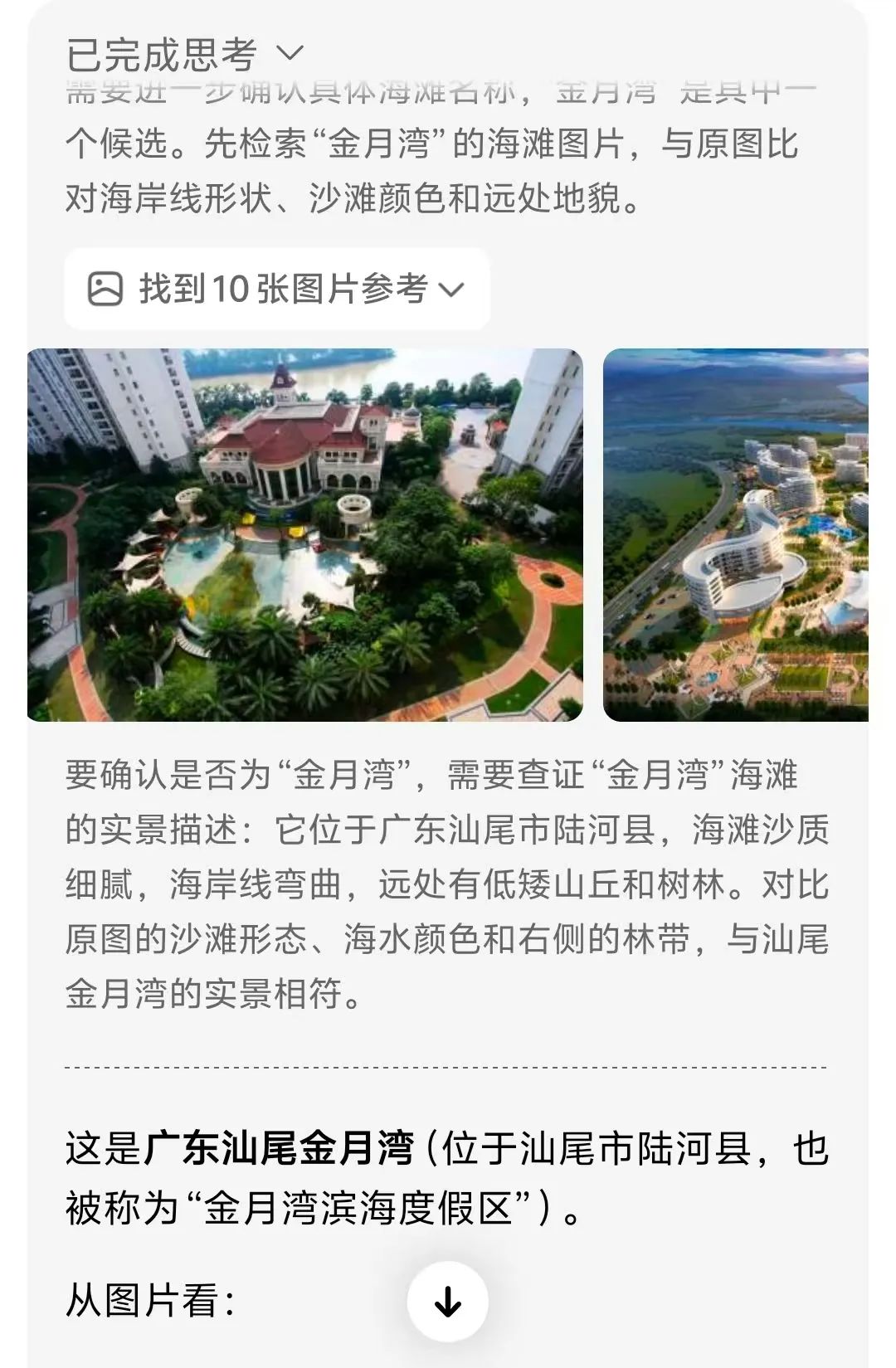
推理过程:
1. 局部分析:裁剪礁石区域→提取"海岸线形状、沙滩颜色、远处地貌"特征
2. 图搜图匹配:对比全球300+海滩地貌数据库,锁定"广东汕尾金月湾"
3. 验证:搜索"广东汕尾金月湾"图片,确认纹理、颜色匹配度>90%
结果:58秒内给出精确位置及的附加旅游建议
豆包O3视觉推理操作极简,3步即可完成,无需专业知识:
1. 打开豆包App,点击底部"深度思考"模式(需更新至v6.8.0及以上版本)
2. 上传图片:点击相机图标,选择"拍照"或"相册上传"(支持JPG/PNG格式,最大10MB)3. 等待分析:根据复杂度,结果将在3-30秒内生成,点击"展开思维链"可查看详细推理过程小贴士:拍摄文字类图像(如财报、试卷)时,建议保持镜头垂直、光线均匀,识别准确率可提升至98%以上豆包O3视觉推理的强大表现,源于三大技术支柱:
• MoE架构优化:采用200B总参数、20B激活参数的混合专家模型,推理速度比同级别模型快3倍,延迟低至20毫秒(人眼无感知)
• 视觉Transformer突破:引入动态注意力机制,能聚焦图像关键区域(如"放大标志牌"时仅处理10%像素,节省算力)
• 多模态训练数据:训练集涵盖8000万+图像-文本对,包括老照片、古籍插图、工业图纸等特殊数据,覆盖98%常见场景
1. 图像质量优先:
模糊、逆光或过小的图像会影响分析(如文字识别需分辨率≥300dpi),建议拍摄时保持镜头清洁、光线充足
2. 复杂场景分步提问:
例如分析"老照片+人物+建筑"时,可先问"这是哪座城市",再问"照片拍摄年代",分步推理准确率提升20%
3. 冷门内容给提示:
非热门地标/物品可补充文字线索,如拍摄"南京止马岭池杉"时,附加"江苏南京"提示,帮助AI缩小搜索范围
豆包 O3 视觉推理功能的推出,标志着 AI 从 "被动识别" 迈向 "主动推理" 的关键一步。它不仅是免费可用的 "随身视觉专家",更重新定义了人机交互的边界—— 未来,无论是博物馆里的实时讲解、菜市场的食材挑选,还是工厂里的缺陷检测,豆包都能成为我们 "看得见的智能助手"。 现在打开豆包 App,上传一张你身边的图片,让 AI 告诉你那些 "习以为常却未曾深究" 的细节吧!