前言
Foreword
机器人行业的“柯达时刻”?
21 世纪初,发明了数码相机的柯达公司因未能拥抱数字革命而轰然倒塌。今天,人形机器人领域正站在一个相似的十字路口。作为行业新贵的特斯拉,做出了一个石破天惊的决定:
抛弃业界公认的 “最佳实践”—— 动作捕捉(motion capture)和遥操作(teleoperation),转而采用一种纯粹的、仅依赖视觉的训练范式。
这并非一次微小的技术迭代,而是一场关于机器如何学习与物理世界互动的根本性哲学分裂。
特斯拉的擎天柱(Optimus)机器人被马斯克寄予厚望,他预测其最终可能占据公司长期价值的 80%,创造超过 10 万亿美元的收入。为了实现这一目标,特斯拉选择了一条无人走过的险路。2025 年 9 月,特斯拉正式发布 Optimus 2.5 版本,其关节设计进一步仿生,手部线条流畅度接近人类,并已在特斯拉工厂试点生产线投入测试。与此同时,第三代机器人 Optimus Gen-3 的设计已进入最终敲定阶段,计划 2026 年量产,目标成本降至 2 万至 2.5 万美元 / 台,灵巧手自由度提升至 22 个,动作精度达 0.02 毫米级。这场豪赌的成败,将重新定义机器人学的底层逻辑。
| 本文作者:余柯 编辑:严紫岩
核心要点
•特斯拉纯视觉,甩遥触
•对手 VR+触觉,砌基石
•赢重新定义,输柯达归零
01
具身智能的困境——触摸,还是不触摸?
要理解特斯拉选择的颠覆性,我们必须首先理解一个在机器人和人工智能领域至关重要的概念:具身智能(Embodied Intelligence)。
1.1 揭开具身智能的面纱
简单来说,具身智能理论认为,真正的智能并非仅仅存在于一个强大的大脑(或算法)中处理抽象数据;它源于一个物理身体、其传感器以及它所处的环境之间动态、持续的反馈循环 。打个比方,这就像学习烘焙蛋糕。一种方式是只阅读食谱(非具身的抽象数据),另一种方式是亲手感受面团的质地,闻到酵母发酵的香气,并根据面团的粘稠度调整水量(具身的体验)。前者可能让你了解流程,但后者才能让你成为真正的大厨。

| 图:具身智能反馈图
这一理论的关键人物,机器人先驱罗德尼·布鲁克斯(Rodney Brooks)在其1991年的开创性论文《没有表征的智能》(Intelligence without Representation)中提出,智能应该从底层、通过感知和运动的交互(如行走和避障)自下而上地构建,而不是从顶层、抽象的推理(如下棋)开始的 。这与传统的符号AI形成了鲜明对比,后者长期挣扎于“符号接地问题”(Grounding Problem)——即如何将内部的抽象符号与现实世界的具体意义联系起来 。
1.2 两大流派的对决
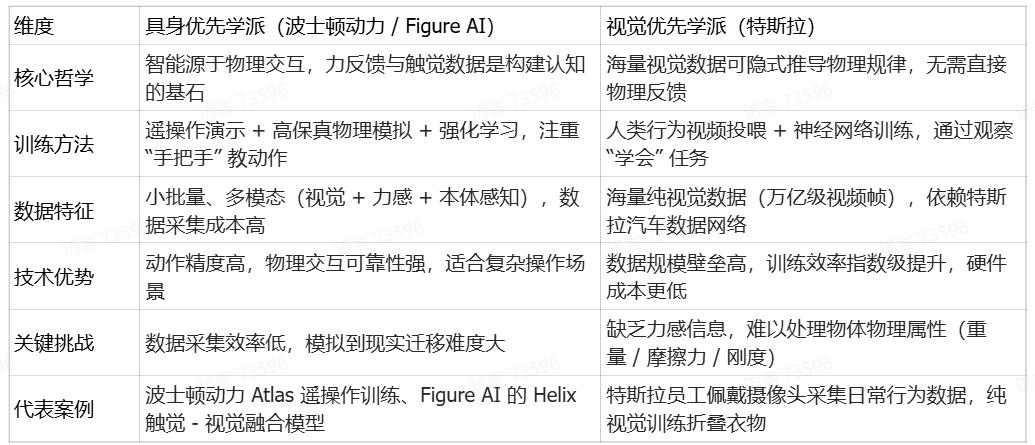
在人形机器人领域,具身智能理论催生了两种截然不同的技术哲学。
“具身优先”学派: 这是行业的主流正统,被波士顿动力(Boston Dynamics)、Figure AI和Agility Robotics等公司所信奉。他们的方法核心是收集来自物理交互的、丰富的、多模态的数据。他们广泛使用遥操作、VR设备、力反馈传感器和高保真物理模拟,来“手把手”地教机器人如何与世界互动 。对他们而言,“触摸”所产生的力、扭矩和触觉数据不是可选项,而是构建可靠物理交互能力的基石 。
波士顿动力 (Boston Dynamics): 其Atlas机器人训练流程是一个迭代循环:首先通过一个集成了VR头显和触觉反馈的先进遥操作平台收集人类演示数据,这些数据同时在真实机器人和高保真模拟中采集 。然后,这些数据被用于训练一个大型行为模型(LBMs),这是一个拥有4.5亿参数的扩散模型,它将语言指令、视觉和本体感知信息映射为机器人的全身动作 。

Figure AI同样采用遥操作收集高质量的人类演示数据,并将其与模拟中通过强化学习(RL)学到的行走策略相结合 。他们的核心是名为Helix的视觉-语言-动作(VLA)模型,该模型能将自然语言指令转化为对机器人上半身的精确、高频控制 。
Agility Robotics为其Digit机器人设计了一套分层智能架构。底层是一个被称为“运动皮层”的基础模型,它通过在NVIDIA Isaac Sim物理模拟器中进行数天的强化学习训练而成,负责机器人全身的平衡和协调 。这个模型可以实现“零样本”迁移到真实世界的机器人上。更上层的规划和认知能力则通过演示学习、遥操作等方式构建 。

特斯拉的“视觉优先”学派: 特斯拉的哲学继承自其备受争议的全自动驾驶(FSD)项目。其核心论点是,只要有足够庞大的视觉数据集和足够先进的神经网络,AI就能够从纯视觉信息中“悟出”底层的物理规律,从而形成对世界的“直觉理解”,而无需直接的物理反馈数据 。他们的目标是通过海量的人类行为视频,让机器人“看会”各种任务 。2025 年 9 月发布的 Optimus 2.5 进一步验证了这一哲学 —— 其隐藏式手部关节设计完全依赖视觉数据优化,已能在工厂环境中完成爆米花分装、挥手互动等任务。
| 图为【机器人产业应用】整理
这种分歧不仅是技术路线的选择,更是一场关于智能本质的深刻哲学辩论。智能,究竟是可以通过大规模被动观察来学习,还是必须通过主动的物理交互来构建?特斯拉用行动给出了它的答案,一个与整个行业背道而驰的答案。
02
规模的福音:
特斯拉为何将赌注全部押在视觉上?
特斯拉的自信并非空穴来风,它源于其FSD项目的成功经验,以及一个任何竞争对手都无法比拟的战略优势:规模。
2.1 FSD剧本的重演
特斯拉的策略是对其FSD项目的直接复制。FSD同样曾做出惊人举动,放弃了激光雷达(LiDAR)和毫米波雷达,坚持纯视觉路线, 其背后的逻辑完全一致:通过将数据收集的规模提升到竞争对手望尘莫及的水平,来实现性能的阶跃。特斯拉内部人士透露,放弃动捕和遥操作,正是为了“更快地扩大数据收集规模” 。
特斯拉通过员工佩戴五摄像头装备采集日常行为数据,其训练效率较传统遥操作提升数十倍。2025 年发布的 Optimus 2.5 已在特斯拉工厂试点生产线部署,通过实时视频流优化装配动作,单台机器人日处理数据量达 TB 级。
传统的遥操作方法,虽然数据质量高,但成本高昂且效率低下。一个操作员在一段时间内只能为一个机器人提供一组演示数据。而特斯拉的新方法,让员工佩戴带有五个摄像头的头盔和背包,在日常工作中就能源源不断地产生训练数据,其数据收集效率呈指数级增长 。
2.2 无可匹敌的数据护城河
这正是特斯拉“牛市”论点的核心。他们的数据优势是压倒性的。
(1)数据量级: 特斯拉在全球拥有超过500万辆配备摄像头的汽车,构成了一个庞大的全球数据采集网络,每年行驶里程高达500亿英里 。其FSD项目已经处理了数以PB计的真实世界视频数据 。其用于AI训练的超级计算机集群,仅热数据缓存容量就超过200 PB 。相比之下,亚马逊 ARMBench 数据集仅 23.5 万个拾取活动,差距犹如溪流与江海。
(2)对比悬殊: 相比之下,即便是最大规模的公开机器人数据集也相形见猧。例如,亚马逊发布的ARMBench数据集包含约23.5万个“拾取活动” 。BridgeData V2包含约6万条轨迹 。两者在数据量上与特斯拉相比,犹如溪流与江海。
(3)未来潜力:马斯克计划 2026 年量产 Optimus Gen-3,其 22 自由度灵巧手将通过全球机器人网络持续采集数据,形成 “舰队学习” 效应,预计五年内数据规模达 FSD 的 10 倍。 马斯克甚至表示,擎天柱的训练需求最终可能是FSD的10倍,而未来由数亿甚至数十亿台擎天柱机器人组成的网络,将成为世界上最大的真实世界交互数据来源 。
特斯拉的战略意图非常明确:他们不仅是在扩大数据收集,更是在试图重新定义机器人学中“有价值的数据”是什么。他们赌的是,极致的数量可以演变成一种新的质量,足以弥补多模态感知信息的缺失。传统机器人学追求的是昂贵、高保真、多模态的“精炼数据”,而特斯拉追求的是廉价、低保真、纯视觉的“海量数据”。其核心假设是,一个神经网络在看过一万亿帧人类开门的视频后,能够比一个只看过一千次高保真遥操作演示的网络,更有效地推断出开门所需的物理知识。这是一个在灵巧操作领域尚未被证实的激进假说。
03
机器中的幽灵:
机器人能从像素中推理出物理定律吗?
现在,我们来到了特斯拉战略的“熊市”论点,也是其面临的最严峻挑战:一个机器人能否仅凭观察,就真正理解物理世界?
3.1“符号接地问题”的终极形态
根本性的挑战在于,视频本质上是三维世界在二维平面上的投影,这个过程必然会丢失信息。正如多位机器人专家指出的,遥操作数据能给予机器人一些视频永远无法单独提供的东西:通过与环境进行物理交互来学习的能力 。没有这种亲身实践的元素,机器人很难将视频中观察到的行为可靠地应用到现实世界中 。
3.2 视频中“隐形”的物理属性包括:
质量与惯性: 面前的箱子是满的还是空的?人类一上手就能凭感觉知道,而纯视觉机器人只能靠猜。:Optimus 2.5 在演示中仍会捏碎纸杯,因其无法通过视觉判断物体刚度。
力与扭矩: 插入插头、拧紧螺丝或打开一个卡住的罐子需要多大的力?视觉无法提供这些直接数据。Gen-3 的 22 自由度灵巧手虽能接住网球,但拧瓶盖时仍需依赖预设力值,缺乏实时触觉反馈。
摩擦力与纹理: 一个表面是光滑还是粗糙?纯视觉机器人也许能看到表面的样子,但无法“感觉”到它的物理特性,而这对于稳定抓取至关重要。即使采用丝杠传动优化动作精度,Gen-3 仍需通过高保真模拟微调,暴露纯视觉路线的局限性。
刚度与可变形性: 一个物体是像木块一样坚硬,还是像布料一样柔软?这对于擎天柱演示过的折叠衣物等任务来说是决定性的 。
3.3 灵巧性的缺失与触觉的首要地位
可以说,视觉对于回答“是什么”和“在哪里”(物体识别、定位)非常出色,但触觉和力反馈对于回答“如何做”(灵巧操作)却是不可或缺的。大量的学术研究反复强调,对于接触丰富的任务, 触觉反馈对接触丰富任务至关重要。例如,折叠衣物时需通过触觉检测布料变形,而 Optimus 2.5 仍依赖视觉估算褶皱位置,导致约 15% 的动作失误率。Gen-3 虽通过丝杠传动提升抓握力控制精度至 0.1N,但缺乏触觉传感器,难以应对表面粗糙度变化。
它为机器人提供了视觉无法捕捉的关键信号,例如调节抓握力、检测滑动、理解接触属性等 。人类能够无缝地整合视觉和触觉信息;剥夺其中任何一种模态,都会造成巨大的能力缺陷 。
3.4 终极的“模拟到现实”挑战
特斯拉的路线可以被看作是“从模拟到现实”(sim-to-real)鸿沟的一个极端版本。在这里,所谓的“模拟”就是那个庞大的、由人类行为构成的二维视频库,而“现实”则是机器人必须在其中操作的、由物理定律支配的三维世界。
这个鸿沟是巨大的。即便使用明确模拟了力和接触的高保真物理引擎,sim-to-real本身已是机器人领域的一大难题。而特斯拉正试图在没有物理引擎的情况下跨越这个鸿沟,寄希望于神经网络能够隐式地学习一个物理世界模型。研究表明,即使是先进的AI视频生成模型,也常常会产生“视觉上逼真但物理上荒谬”的内容,这凸显了从像素中学习物理的艰巨性 。
因此,特斯拉战略的成败,完全悬于一个未经证实的信仰之跃:一个神经网络是否能够仅从视觉数据中,构建出一个足够准确且可泛化的隐式物理世界模型。这是其最核心的技术瓶颈,也是风险最大的地方。如果失败,擎天柱可能永远无法摆脱笨拙、不可靠甚至危险的标签。它可能会捏碎一个它以为是易拉罐的纸杯,或者因为它无法施加正确的力而打不开一扇门。这正是“具身优先”学派从一开始就极力避免的致命缺陷。
04
通往未来,还是走向死胡同?三种可能性的权衡
综合以上分析,特斯拉擎天柱的未来似乎有三种可能的剧本。
(1)牛市剧本 - 范式转移。若 Optimus Gen-3 通过 22 自由度灵巧手和全球数据网络实现物理规律的隐式学习,其 2 万美元成本将颠覆行业。特斯拉计划 2026 年量产 10 万台,率先应用于仓储分拣、家庭服务等场景,目标效率较人工提升 50%,这将是一场彻头彻尾的革命。他们将证明,只要有足够的数据和算力,AI确实可以仅从观察中“重新发明物理学”。这将使得缓慢、昂贵且复杂的遥操作和模拟训练方法,在通用技能学习方面变得过时。特斯拉的数据护城河将变得真正无法逾越,可能为他们带来长达十年的领先优势,并使其能够以一种验证马斯克宏大财务预测(贡献超过10万亿美元市值)的成本和规模,来生产通用人形机器人 。
(2)熊市剧本 - 撞上物理之墙。根据许多机器人专家的观点,这是一种可能性更大的情景 。纯视觉路线最终会撞上一堵坚硬的能力天花板。擎天柱机器人或许能熟练地模仿任务的 运动学(动作的几何形态),但在动力学(所涉及的力)方面却一败涂地。它们可以在受控的演示中折叠衣物,却无法可靠地处理现实世界中物体的多样性和不可预测性。
这将迫使特斯拉进行一次代价高昂且颇为尴尬的战略撤退,重新整合他们刚刚抛弃的遥操作和模拟系统。他们将失去关键的哲学差异化优势,并面临严重的研发延迟,从而让那些基础更扎实的竞争对手迎头赶上。 例如,Gen-3 虽能模仿人类开门动作,但无法应对门把手生锈等异常情况,迫使特斯拉重新整合遥操作系统。
(3)混合假说 - 务实的中间路线。这或许是最可能发生的未来。特斯拉的纯视觉方法并非一个完整的解决方案,而是解决问题中某个环节的强大新工具:大规模行为预训练。在这个场景中,特斯拉利用其庞大的视频库,训练出一个掌握了海量人类行为词汇的“常识”基础模型(解决了90%的问题)。
这个模型可以被快速地针对特定任务进行微调。然而,为了实现商业部署所需的最后10%的可靠性、灵巧性和安全性,这个预训练模型必须被“接地”。 Optimus 2.5 已验证视觉预训练的可行性,而 Gen-3 的量产版本可能通过小规模触觉传感器(如力矩反馈)实现 “最后 10% 的可靠性”。这种 “视觉优先 + 具身收尾” 策略,既能利用特斯拉的数据优势,又能规避物理交互短板。

| 图为【机器人产业应用】整理
05
结语:回路中的人类
特斯拉的 “视觉优先” 实验,本质是对智能本质的激进叩问:当机器拥有万亿级视觉数据时,能否跳过物理交互直接 “顿悟” 世界规则?这场豪赌的终极意义,或许不在于胜负,而在于撕开了机器人学的底层矛盾 —— 数据规模与具身经验的博弈,正在重塑智能的定义。
无论结果如何,特斯拉已迫使行业正视一个现实:互联网级数据正在成为新的生产力。其价值不仅在于技术验证,更在于推动整个领域突破路径依赖 —— 当波士顿动力们用精密传感器构建 “数字肉身” 时,特斯拉用像素洪流浇筑 “视觉灵魂”,两者共同勾勒出智能进化的双轨图景。或许,真正的答案藏在两者的融合之中:视觉提供行为认知的广度,具身赋予物理交互的深度。而人类在这场探索中最深刻的发现可能是:那些我们习以为常的抓握、行走等动作,实则是生物进化亿万年的具身智慧结晶,机器要复刻这种 “身体记忆”,既需要数据海啸的冲刷,也离不开物理世界的 “触摸觉醒”。
———————————————————