告别Reasoning模型的“灵光一现”,推理能力可控了
项目简介
为什么说模型的“灵光一现”不可靠?
当前像GPT-4o、DeepSeek-R1等大模型虽然能生成复杂推理链,但它们的“高级操作”(比如自我纠正、反向验证)往往是随机触发的,就像突然的“灵光一现”。这种不可控性导致:
同一问题可能得到不同答案 复杂任务容易“翻车” 难以规模化应用

论文地址:
突破点:教会模型三种“元能力”
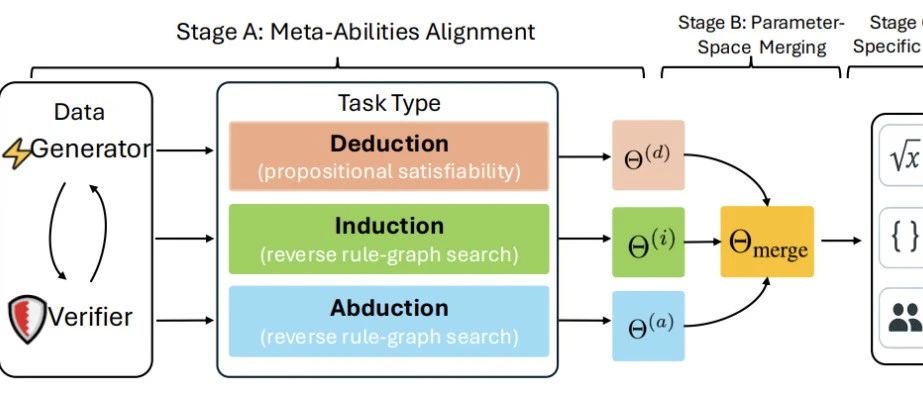
“元能力构成统一推理框架”示意图
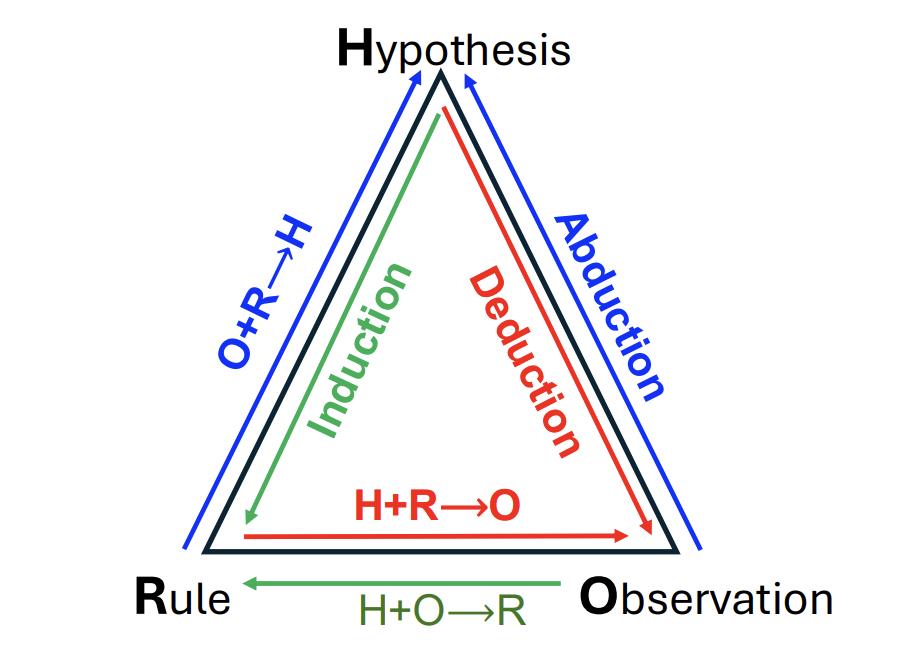
研究者从哲学中的经典推理三要素获得灵感:
演绎(Deduction):已知规则和假设,推导具体结果 例:数学公式推导 归纳(Induction):从现象总结规律 例:观察数列猜规律 溯因(Abduction):从结果反推原因 例:侦探破案找线索
为了训练这些能力,团队设计了程序化生成任务:
演绎特训:解逻辑谜题(如命题可满足性问题) 归纳特训:补全隐藏规律的序列 溯因特训:反向搜索规则图谱
三步走
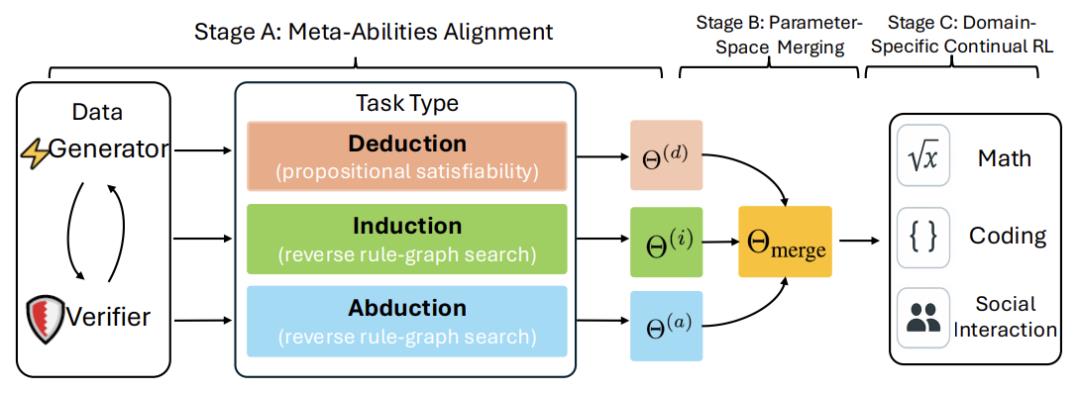
三阶段训练流程图
第一阶段:分模块特训
每个元能力单独训练专家模型,用强化学习(RL)奖励机制引导学习。例如:
奖励公式:总奖励 = 格式分 + 答案分
答案正确得+2分,格式错误扣-1分
第二阶段:参数空间融合
把三个专家模型的参数按权重合并:
合并后模型 = λ?×演绎专家 + λ?×归纳专家 + λ?×溯因专家
(λ是调整权重的系数,实验发现演绎能力更重要)
第三阶段:领域强化学习
在数学、编程等具体领域继续训练,进一步提升性能。
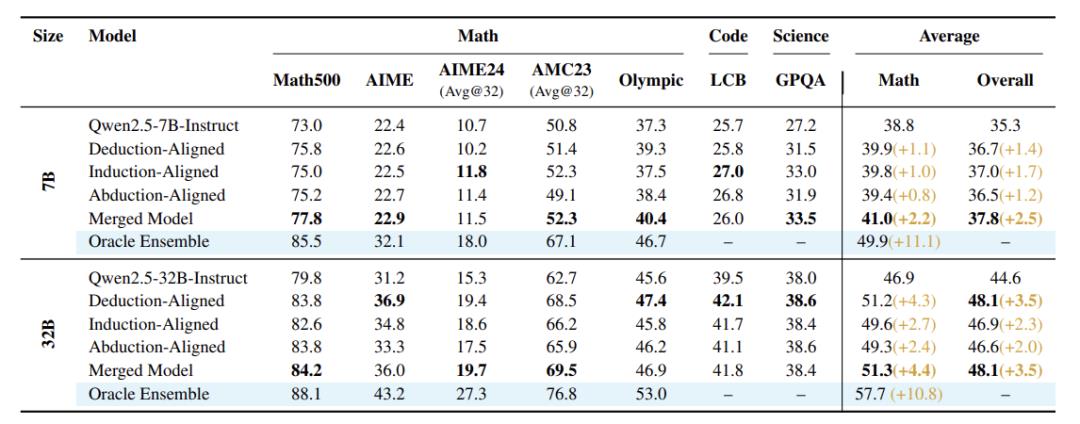
效果起飞
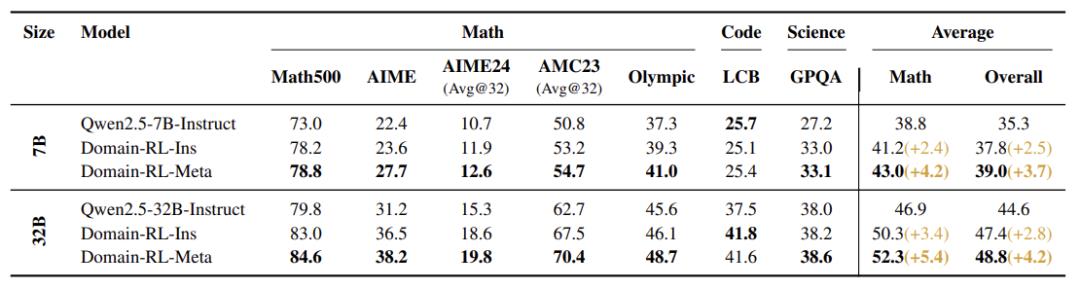
7B模型:数学平均分从38.8%→43.0%,提升4.2% 32B模型:科学问答(GPQA)准确率从38.0%→38.6% 融合模型比单个专家模型强10%以上 模型越大,提升越显著:32B模型比7B多涨2%
这波操作对我们行业意味着什么?
告别玄学:推理能力从“随机触发”变为“可控培养” 可解释性增强:明确知道模型用了哪种推理模式 应用潜力:数学解题、代码生成、科学推理等领域将更可靠
标签 AI