音频驱动的人体动画技术已取得显著进展,但现有方法主要集中于面部动作,难以实现自然同步和流畅的全身动画生成,同时在精细化生成中的提示词控制方面也存在局限。为了解决这些问题,阿里巴巴夸克团队推出了OmniAvatar —一种创新的音频驱动全身视频生成模型,在提升口型同步精度和自然动作表现方面实现了突破。(链接在文章底部)
OmniAvatar 这是一种用于音频驱动的全身视频生成的新型模型,能够提升生成人物头像的自然性与表现力。通过引入逐像素多层次音频嵌入策略 并结合 基于 LoRA 的训练方法,该模型有效解决了唇动同步与真实动态身体动作生成的核心挑战。在面部及半身视频生成方面均优于现有模型,并能够基于文本提示实现精确控制,适用于播客、人际互动、动态场景和歌唱等多种视频生成领域。
01 技术原理
—
OmniAvatar 旨在通过一张参考图像、音频和提示词作为输入,生成具备自适应且自然全身动作的说话虚拟人视频。模型的整体架构如图所示。为多层次捕捉音频特征,提出了多层级音频嵌入策略,以保持音频与视频之间的逐像素对齐。
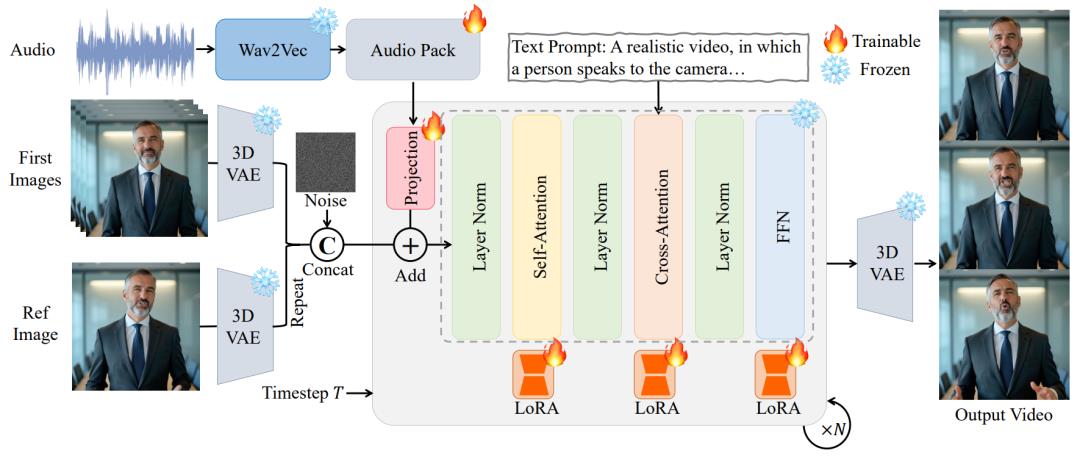
此外,为了在引入音频作为新条件的同时保留基础模型的强大能力,在DiT 模型 的各层中引入了基于 LoRA 的训练方法。为了在长视频生成中保持一致性与时间连续性,还引入了帧重叠机制与参考图像嵌入策略。
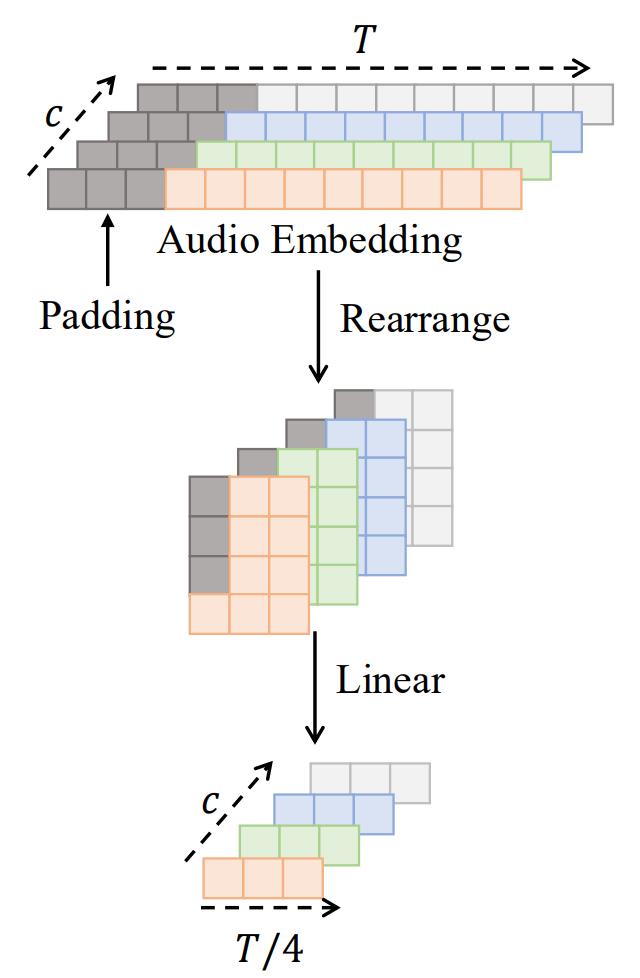
音频包(Audio Pack)的设计:为了将音频特征对齐到潜在空间,Audio Pack 首先对填充后的音频进行重新排列,然后通过一个线性层将其映射为音频潜在表示(audio latent)。
得益于Wan2.1-T2V的文本控制能力以及设计的 LoRA 训练方法,模型不仅能够根据音频生成自然的人体动作,还支持虚拟人与周围物体的交互。
OmniAvatar 还支持手势控制和背景调整,使其成为适用于多种场景的动态、交互式音频驱动视频生成强大工具。
OmniAvatar 可以通过提示词控制角色的情绪,如开心、愤怒、惊讶和悲伤。
尽管 OmniAvatar 在音频驱动视频生成上取得进展,但仍有局限。模型继承了基础模型的缺陷,如颜色偏移和长视频误差累积,导致长视频效果下降。LoRA虽保留了模型能力,但复杂文本控制仍难以区分发言角色或多角色交互。且扩散推理需多次去噪,推理时间长,难以满足实时交互需求。
https://github.com/Omni-Avatar/OmniAvatarhttps://arxiv.org/abs/2506.18866https://huggingface.co/OmniAvatar/OmniAvatar-14B