AI产品经理做研究:每个大模型的幻觉将会被解决,准确率99%

我们提出“置信深度思考”(DeepConf)——一种简洁而有效的测试时方法,它把并行思考与基于局部置信度的过滤相结合。DeepConf 同时支持离线模式和在线模式:既可以在生成过程中、也可以在生成完成后,识别并丢弃低置信度的推理轨迹。该方法在不降低、甚至提升最终答案准确率的同时,显著减少了不必要的 token 消耗。
当然现在这个算法的限制还是在参数娇小的模型里成功了,研究团队在8B~到120B的参数模型里,完成了99%的模型识别准确率。
在实验结果里,DEEPConf的准确率超过了其他的算法模型,并且也减少了相当多的资源浪费。
在可访问全部推理轨迹的离线模式下,DeepConf@512 在使用 GPT-OSS-120B(无工具)时,在 AIME 2025 上达到 99.9% 的准确率,彻底刷爆该基准;相比之下,cons@512(多数投票)为 97.0%,pass@1 仅为 91.8%。在具备实时生成控制的在线模式下,DeepConf 相比标准并行思考最多可减少 84.7% 的 token 消耗,同时保持或超越原有准确率。图 1 展示了我们的主要结果
并且这个算法支持在线与离线两种模式,离线模式需要更多的算力资源,而在线模式的效果就不如离线好。
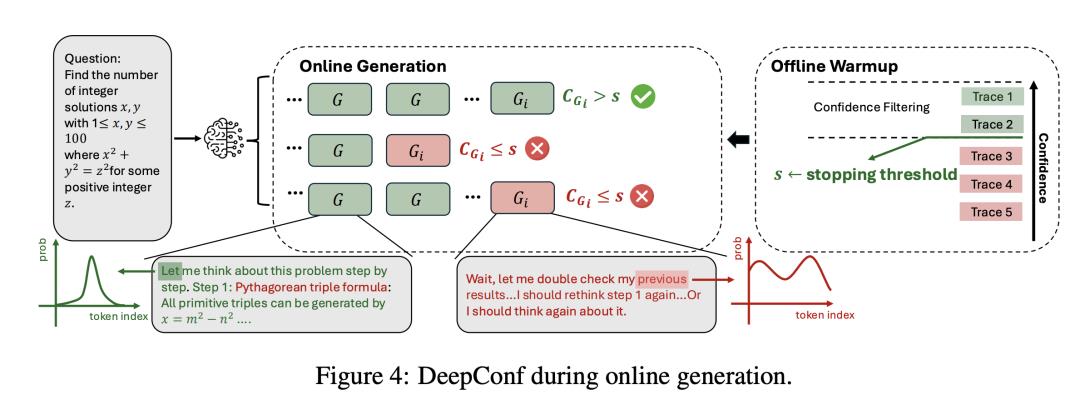
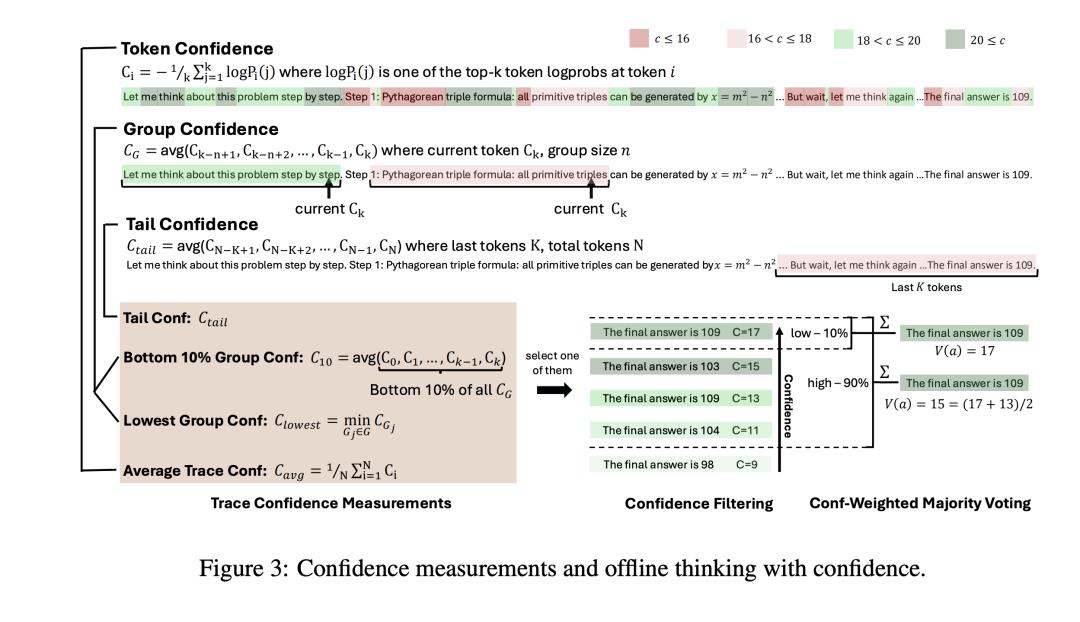

从现在来看,要实现模型的识别率提升到99%,没有幻觉,就加上这以上几行代码就可用了
附录里给了 vLLM 修改不到 50 行的伪代码,简单直接,甚至直接pull mr即插即用。如下是附录代码内容


总的来说,将其性能可以提升,如果针对自己要节约训练时间的,可以用think confen算法来提升。
这种没有监督的自我监督学习方法,虽然就增加了算力要求,但是确实将幻觉降低到了1%。
今天的分享就到这里
文献地址:https://arxiv.org/pdf/2508.15260