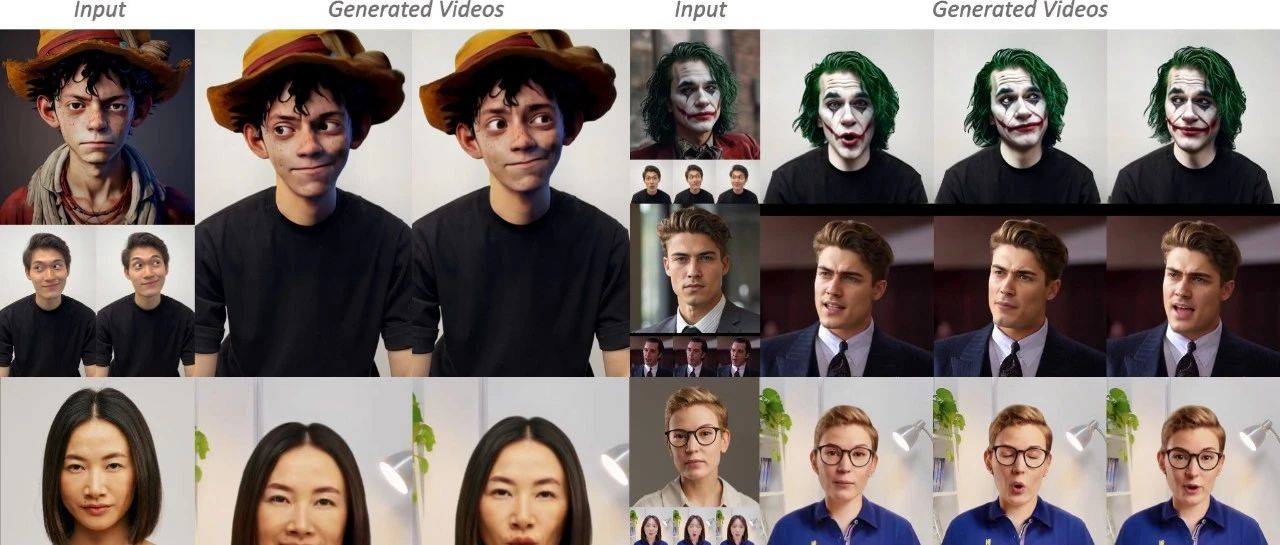
如何自然地将一张人像照片中的头部替换到一段动态视频中,并能自由调整表情和动作?传统的人脸替换方法通常只处理面部区域,容易忽略整体头部的结构,像是发型、头型等;而已有的头部替换技术在面对复杂背景和多样化发型时容易“翻车”,更别说在替换之后还能让头部表情动起来了。为了解决这些痛点,阿里巴巴通义实验室提出了一种全新的基于扩散模型的视频头部替换方法,不仅能无缝融合原视频背景和身体,还允许用户灵活控制表情和头部动作,带来更自然、灵活的换头体验。
这项方法背后融合了多个关键创新点。首先,采用了一种对头部形状不敏感的智能遮罩策略,能够有效地将头部特征从复杂背景中分离出来,并通过专门的发型增强机制,确保不同发型下的身份一致性。其次,在表情控制方面,引入了一个基于3D人脸模型(3DMM)的重定向模块,它能够将身份、表情和头部姿态分别处理,从而消除原始表情对最终效果的干扰,同时还支持后期自定义修改。为提升表情迁移的精度,还设计了尺度感知的策略,有效降低了不同人物之间表情“错位”的风险。(链接在文章底部)
01 技术原理
—
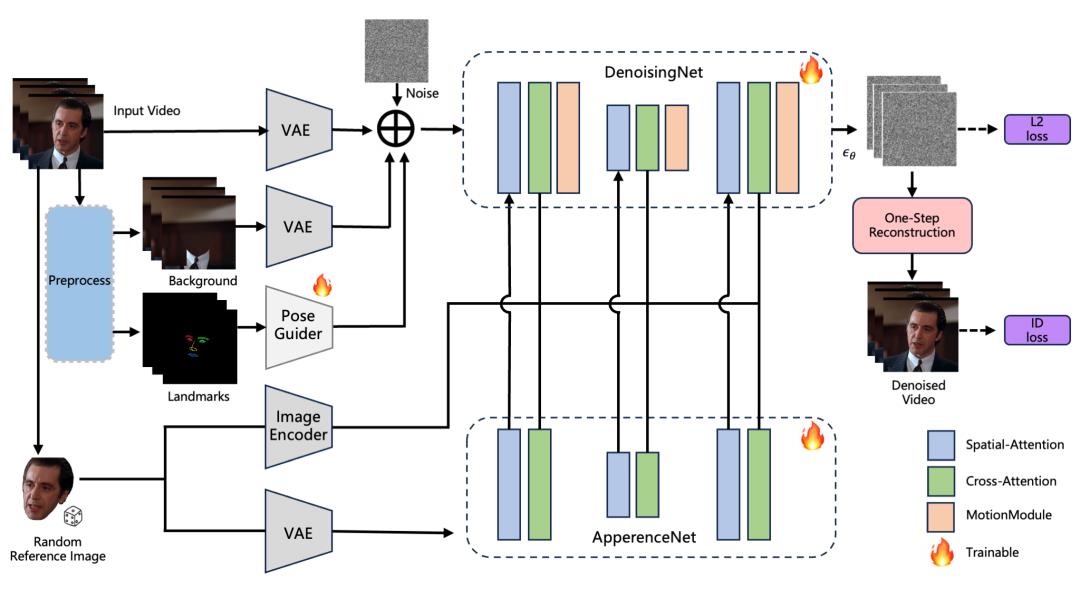
方法的整体框架如下:在训练阶段,首先对输入视频进行预处理,提取出修复后的背景图,并利用Mediapipe 检测 3D 关键点。修复背景图与 3D 关键点将作为条件输入,同时从视频中随机选取一帧作为参考图像。接着,从输出噪声中重建图像,并在像素级引入额外的身份损失,以增强身份一致性。
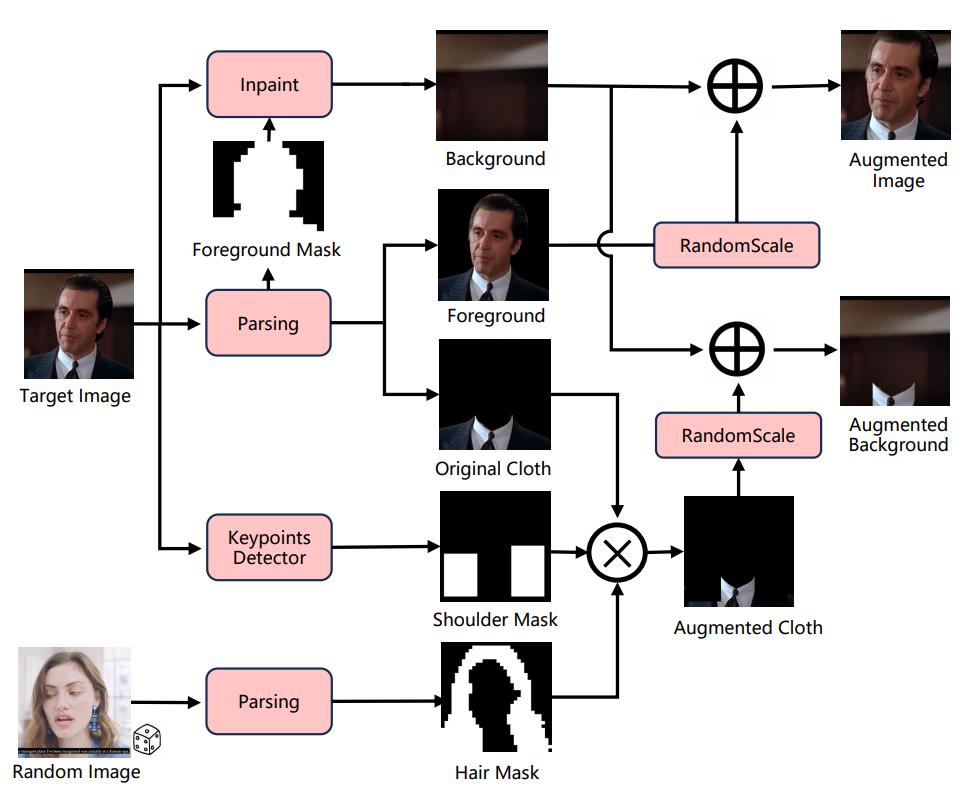
形状无关遮罩与发型增强策略的细节如下:对于给定的目标图像,首先提取前景掩码和衣物掩码。随后,应用形状无关的遮罩策略来扰乱分割边界,并生成修复后的背景图。前景图像会被随机缩放后与背景图合成,形成用于训练的数据增强图像。
此外,随机选取一张长发图像以提取头发掩码,并通过 Mediapipe 检测肩部关键点生成肩部掩码。最终,将原始衣物、肩部掩码和头发掩码组合在一起,作为输入提供给稳定扩散模型(Stable Diffusion, SD)。
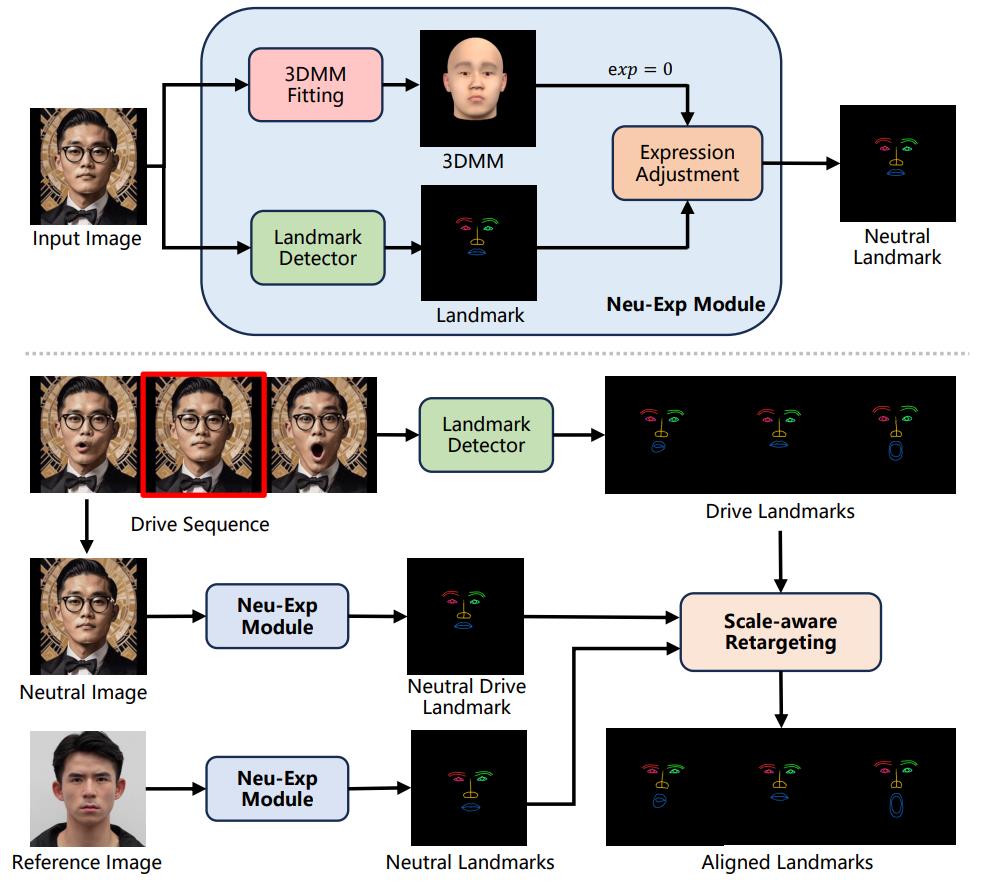
表情感知关键点重定向的细节如下:Neu-Exp 模块利用 3DMM 模板对输入图像中的表情进行中和处理,输出中性化的关键点。在进行表情迁移时,从驱动序列中选取一帧接近中性的图像,并通过 Neu-Exp 模块获得其中性的驱动关键点。随后,采用尺度感知重定向策略,生成与源图对齐的关键点,以实现更精确的表情迁移。
02 对比与演示效果
—
与当前几种主流的面部替换方法(SimSwap 、DiffSwap)、头部替换方法(HeSer)以及人像动画方法(Follow-your-emoji和 AniPortrait)进行了对比。

面部替换方法通常难以有效迁移头部形状与发型,导致身份一致性较差,其中 DiffSwap生成的图像还存在较明显的模糊问题。头部替换方法虽然能转移整个头部,但容易引入背景伪影、表情迁移不准确以及身份偏移等问题。
https://arxiv.org/pdf/2506.16852