主要原因上下文窗口的限制,每个大模型都有上下文长度上限(比如 8k、32k、甚至 200k tokens)。
而一本英文书动辄几十万、上百万 tokens,远远超出模型的上下文容量。
牛逼的如Gemini,号称100万Token,拿去翻译,完全不着调,很容易在长文本里出现丢失细节,最后出现:
总结代替逐句翻译,这可出大问题了!


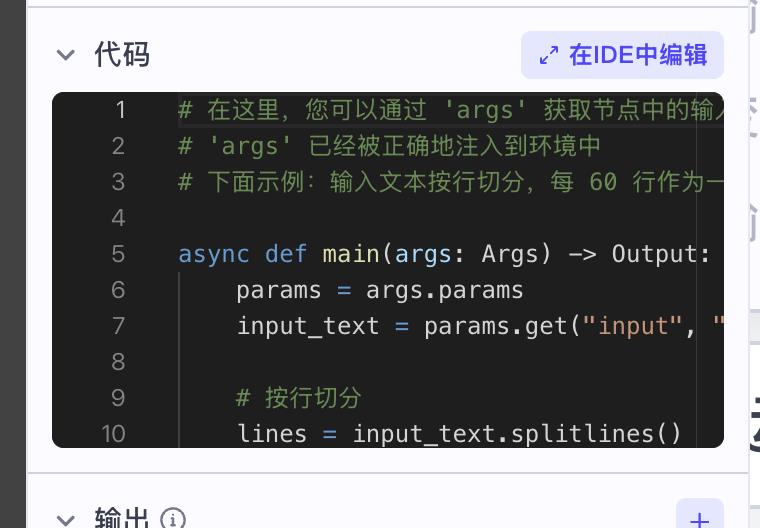
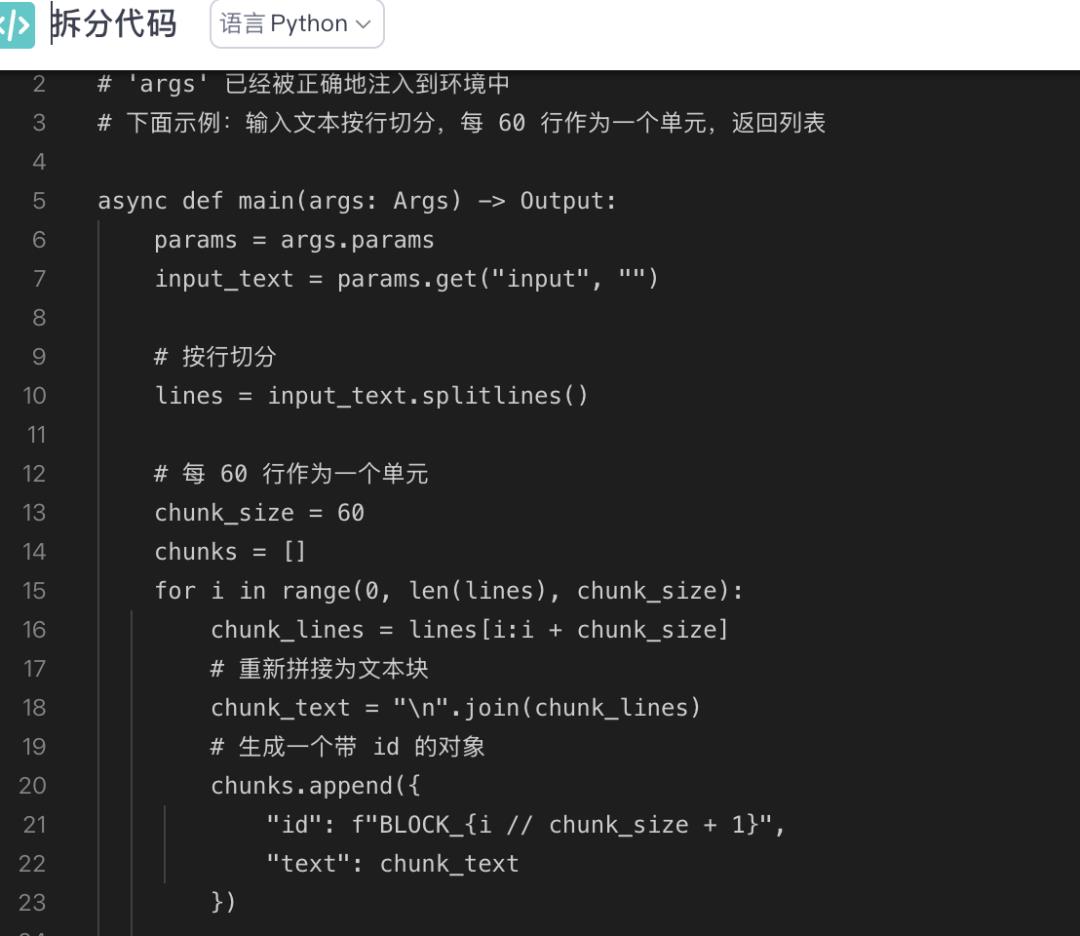
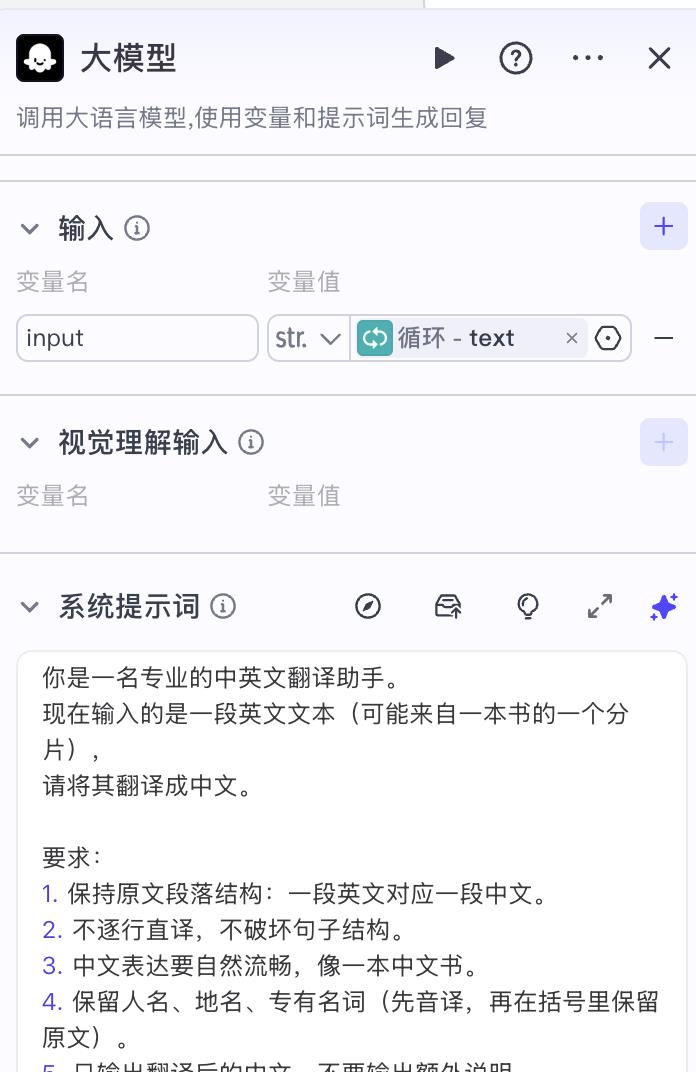
你是一名专业的中英文翻译助手。现在输入的是一段英文文本(可能来自一本书的一个分片),请将其翻译成中文。要求:1. 保持原文段落结构:一段英文对应一段中文。2. 不逐行直译,不破坏句子结构。3. 中文表达要自然流畅,像一本中文书。4. 保留人名、地名、专有名词(先音译,再在括号里保留原文)。5. 只输出翻译后的中文,不要输出额外说明。
很多人觉得“整本英文书翻译成中文”是一件不可能的任务,但实际上只要思路对了,难度就能被大幅降低。
靠单个大模型硬吃完整本书,必然会遇到上下文长度、稳定性、风格一致性等一系列问题。
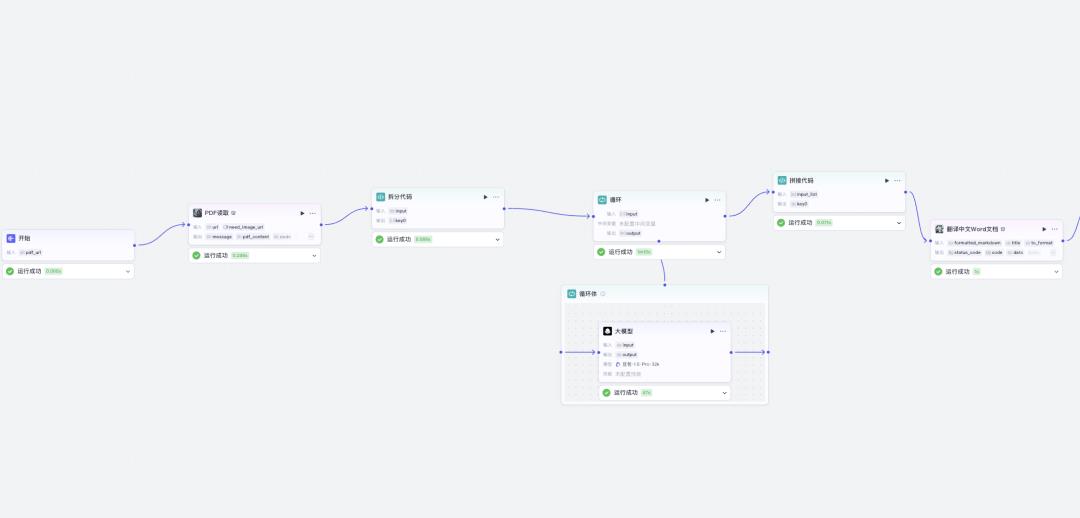
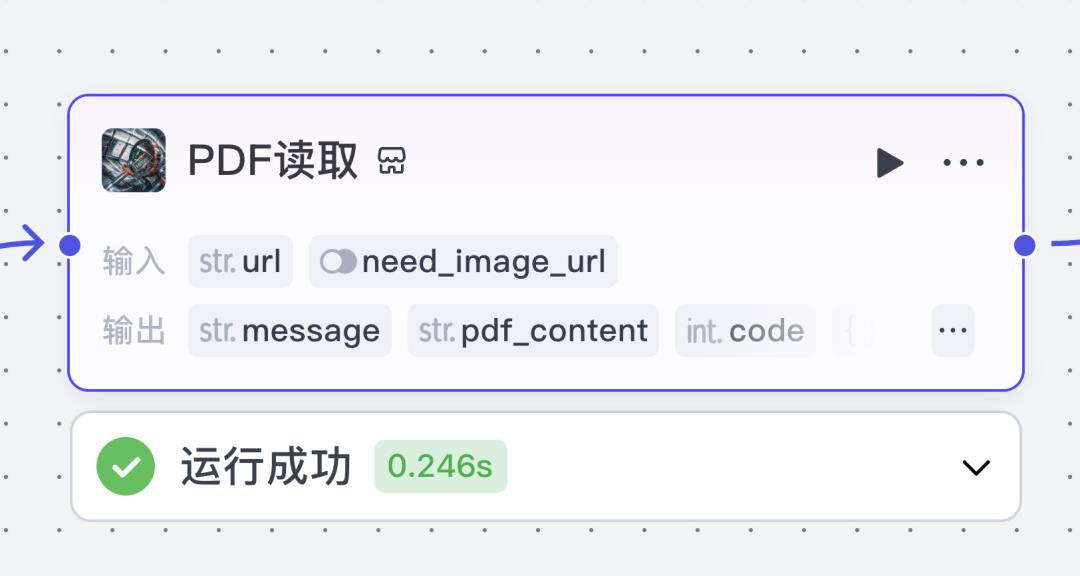
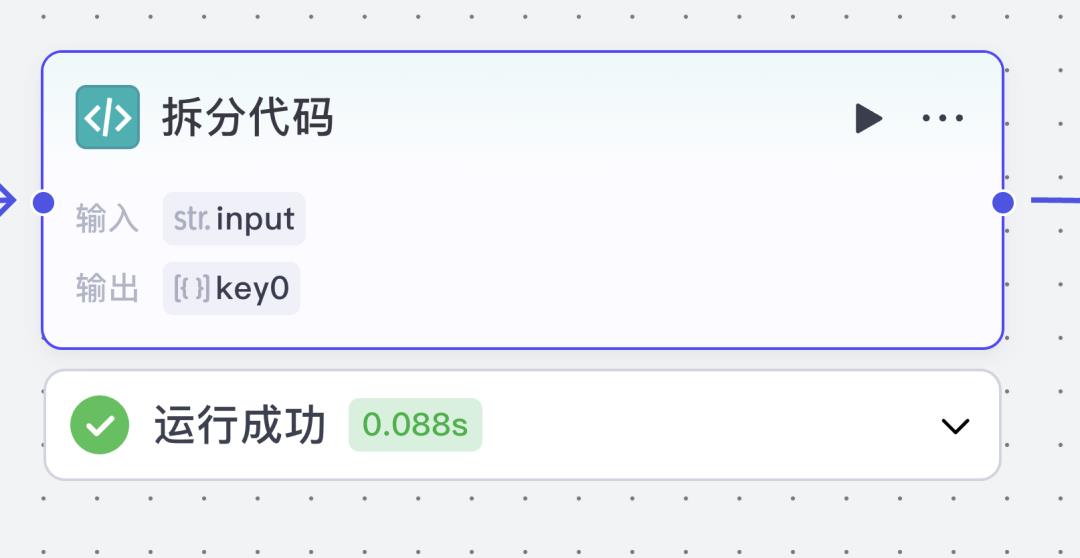
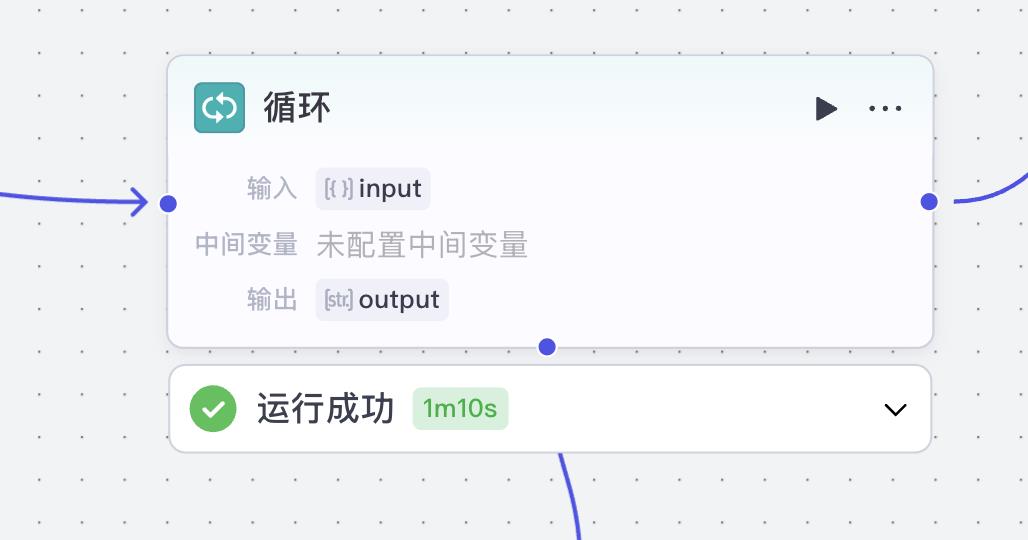
但如果换一种方式,把 大模型当作工作流的一个环节,让它专注于自己最擅长的短文本翻译,然后通过 智能体 + 流程自动化 去串联拆分、翻译、拼接、导出,就能轻松解决“长文档逐句翻译”的老大难问题。
简单来说,这个方案的优势有三点:
精准:每个分片逐句翻译,避免模型偷懒总结。
高效:整套流程自动化,翻译完一本书只需人工最后过一遍。
可扩展:不仅能翻译书籍,也能处理论文、专利、报告等长文档。
当然还有其他更多方法,后面的文章我再分享。
以上全文1350字,12张图。如果觉得这篇文章对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个??,谢谢你看我的文章,我们下篇再见。
标签 AI