现在大语言模型处理长文本特头疼:字一多,token数量就炸了,又费钱又慢。
结果DeepSeek团队盯着这问题琢磨,突然发现个事儿:一页文字纯文本输进去,得2000到5000个token,可要是渲染成图片,用视觉模型处理,居然只要200到400个视觉token!
压缩率直接飙到10倍,这差距也太离谱了。
结果还真让他们搞出来了,就是这个DeepSeek-OCR。

说穿了,这模型的核心想法特简单:用视觉感知帮长文本瘦身。
就像DeepSeek在报告里说的,靠这招能把不同阶段的文本token减7到20倍,算是给长文本处理开了条新路子。
其实想想也合理,DeepSeek团队一直就爱琢磨用更少资源干大事,之前做的模型就想跟OpenAI、谷歌掰掰手腕,现在把这思路用到OCR上,倒也不意外。
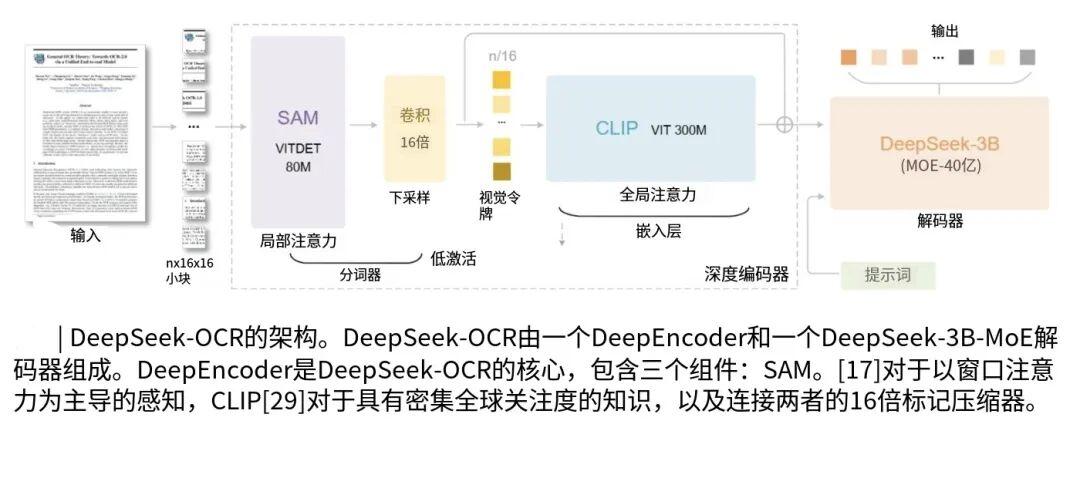
再说说它是怎么干活的,其实就两步:先把文字变成图片,用个视觉编码器(叫DeepEncoder)压小,再用个文本解码器(DeepSeek-3B-MoE)把字重建出来。
我特地扒了扒这个DeepEncoder,这才是真脑洞:把两个知名视觉模型拼一块儿了,SAM-base负责盯细节,比如字的笔画、排版。
CLIP-Large负责看整体,把握页面结构。
中间还加了个16倍的卷积压缩模块,就拿1024×1024的文档图来说,普通视觉模型得出4096个特征块,它一压缩,只出256个视觉token!
这下就不用怕特征量爆炸,后续处理又快又省内存,这设计是真够巧的。
解码器那边呢,是个小尺寸的专家混合模型,总共5.7亿活跃参数,里面藏着64个小专家,每次解码只叫醒6个干活,从压缩后的视觉特征里一点点把文字抠出来。

最牛的是,它训练时啥都学了,不光普通文档,连表格、公式、化学分子结构、几何图形都能认,还能处理多语言PDF。


要知道,这些结构化信息,好多传统OCR碰都不敢碰,它倒好,全给包圆了。
还有个细节特贴心:它能根据文字密度和版面复杂度调压缩程度。
比如遇到特别大、特别复杂的页面,就开Gundam模式,跟InternVL2.0似的分块处理。
简单页面就少用点token省劲儿,复杂页面就细分保证accuracy,算是把效率和准确平衡得挺好。
说真的,这思路就像给长文本做有损压缩,借视觉模态信息密度高、冗余少的特点,少用token还能存住信息。
这模型终于开源了,我第一时间就去GitHub瞅了眼,权重和代码全放出来了,还用的MIT许可证,学术研究、商业应用随便用,对开发者来说简直是福利!
模型文件大概6.6GB,对应30亿参数规模,不过得用NVIDIAGPU跑,还得装Python3.12+、PyTorch2.6.0这些。
官方给的教程特详细,连怎么用Transformers库加载模型、调参数都写了,甚至还有PDF解析的示例脚本,连vLLM加速方案都给配了,社区还有人做了Docker镜像和Web界面,只要有点深度学习基础,基本都能跑起来。
不过有个小门槛,得有16GB以上显存的GPU。
再说说它的性能,我看测试数据的时候是真惊了!
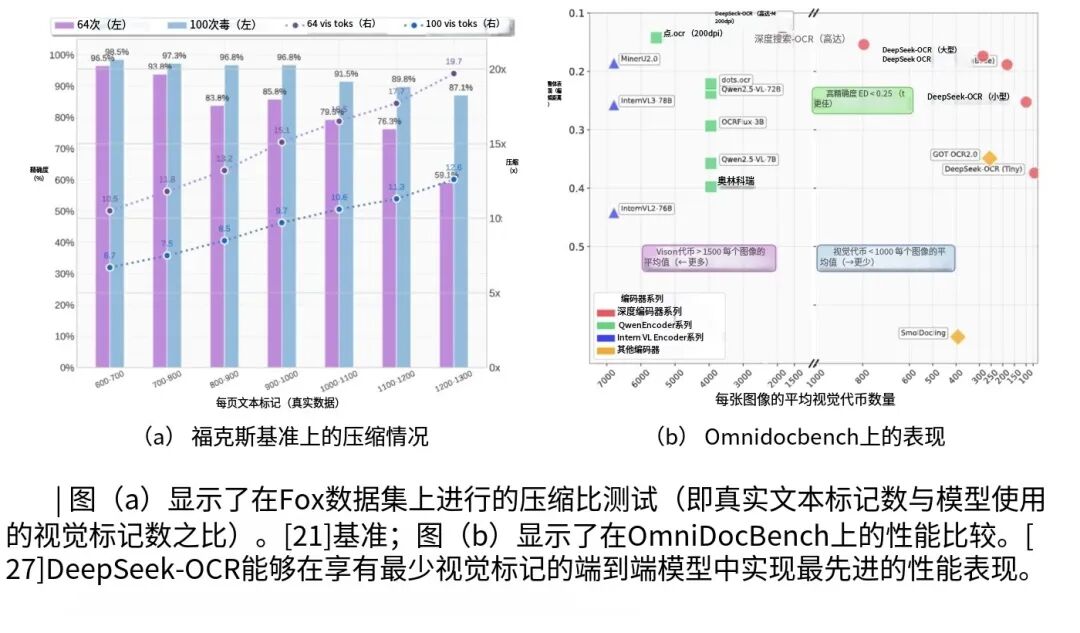
在Fox基准测试里,用64个视觉token处理每页600-700个文本token的文档,准确率能到96.5%,压缩率6.7倍,加到100个视觉token,准确率直接飙到98.5%,压缩率10.5倍!
就算是每页1200-1300个token的密文,100个视觉token也能保59.1%的准确率,压缩快20倍!
速度也够能打,单张A100GPU一天能处理20万页文档,20台服务器(每台8张A100)一天能搞3300万页,对付大规模文档数字化完全没问题。
而且它参数才3亿级别,部署在本地或边缘设备都方便,延迟还低。
当然也不是没缺点,压缩到20倍以上,准确率就掉得明显,太复杂的版面或冷门字体也可能认错,但这些都是OCR领域的老难题了,DeepSeek-OCR能做到这份上,已经很能打了。
说实话,这模型能用到的地方太多了,处理长篇PDF、书籍扫描件,帮法律、金融、科研行业省时间。

支持100多种语言,跨国公司处理多语言报表、图书馆扫多语种古籍都能用。

未来这方向也挺值得期待的。
比如把它跟对话AI搭一块儿,用户传长篇文档,先用它压成视觉特征,再给语言模型处理,就能突破输入长度限制。
DeepSeek用这思路做对话记忆,人记东西会慢慢模糊一样,让模型把旧对话存成低分辨率记忆图,扩内存容量,这想法也太妙了。

而且它可能会改变OCR的技术路线,以前都是检测+识别,现在端到端的多模态OCR开始冒头了。
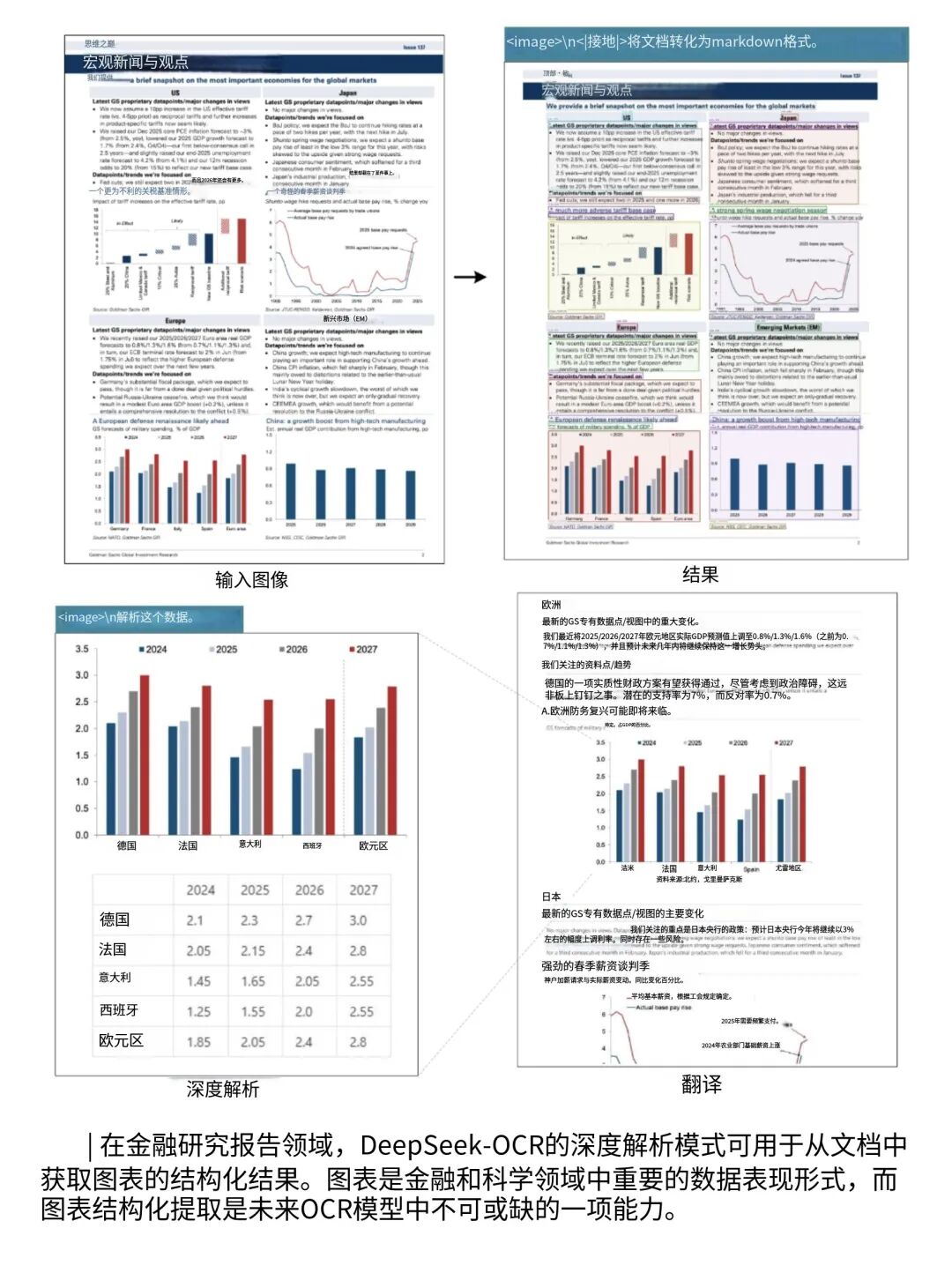
以后的OCR说不定不仅能识字,还能理解内容,直接出结构化结果,比如DeepSeek-OCR已经能处理图表出Markdown、认化学式出SMILES编码、看几何图形出坐标,以后只会更智能。

总的来说,DeepSeek-OCR不光是OCR领域的突破,更是AI多模态融合的一块里程碑。
它证明把文字当图片压缩这疯狂想法真能行,也给长文本处理找了条新路子。
就像DeepSeek在报告里说的,这只是对视觉文本压缩边界的初步探索,现在已经这么惊艳了,以后肯定还有更大的空间。
说不定再过阵子,大语言模型的脑子里,不只是抽象的文字token,还会存着一堆压缩的记忆图片,帮它更好地处理海量信息。
DeepSeek这波操作,是真敢想,也真做成了。
这场关于文字变图片的AI变革,才刚开头呢。