几年前刚转做 AI 产品时,我跟技术同学开需求会,对方一句 “这个功能得先看基座模型的预训练数据覆盖度,后训练用 RLHF 还是 SFT 得再评估”,直接把我干懵了。今天就用大白话,以产品经理的视角深入浅出地跟大家聊聊 “大模型” 到底是什么,怎么训练出来的,怎么应用。一、大模型不是 “无所不能”,它本质是个 “会学语言的函数”“大语言模型(LLM)” 里,藏着三个关键密码 ——模型、语言、大,少一个都不行。做个简单的比喻:“就像你手机里的计算器 APP,输入‘1+1’,它输出‘2’,大模型也是个‘输入转输出’的函数 y=f (x),只不过输入是你的问题,输出是回答。” 比如我们做客服 AI 时,输入 “怎么申请退货”,模型输出退货步骤,本质就是这个函数在工作。但和计算器不同的是,大模型的 “函数逻辑” 不是写死的代码,而是靠数据 “喂” 出来的。语言是人类传递信息的核心载体,大模型之所以被认为 “有智能”,关键在于它能真正 “理解” 语言 —— 不只是识别文字,还能 get 到语境、语气甚至潜台词。比如你说 “这方案有点‘绕’”,它知道你是觉得逻辑不清晰,而不是真的在说 “绕圈”。
我之前试过用小模型做评价分类,它只会机械匹配 “差评”“不好” 这样的关键词,遇到 “虽然便宜但质量一言难尽” 这种委婉表达就懵了,换成大模型后,准确率直接从 60% 提到了 90%,这就是 “懂语言” 的威力。这是大模型比以前的 AI 强的核心原因,背后是 “缩放定律”:模型参数越多、训练数据越海量,它的 “智能程度” 就越高。举个直观的例子:早期的 AI 只能做单一任务(比如识别图片里的猫),而现在的 GPT-4o 能同时写代码、做数据分析、编故事,靠的就是 “大” 带来的泛化能力。
二、大模型是怎么练成的?从 “狂背书” 到 “练实操”
大模型的训练过程,和人类从学生到职场人的成长路径几乎一模一样,分两个阶段:
第一阶段:预训练 —— 像大学生 “狂刷通识课”
这一步的目标是让模型 “博览群书”,掌握海量知识和语言规律。它会 “读” 遍互联网上的维基百科、开源代码库、书籍论文 —— 你能想到的文本数据,几乎都被它纳入了学习范围。
但这一步的 “成本高到离谱”:占据整个训练成本的 99%,需要成千上万的 GPU 集群跑几个月。比如 Meta 的 Llama 3.1 405B 模型,用 24000 张 H100 显卡训练了 54 天,普通人根本玩不起。
不过别觉得这步 “浪费”—— 预训练就像给模型打下 “知识地基”,没有这一步,后面再怎么教,它也成不了 “多面手”。
第二阶段:后训练 —— 像职场新人 “练实操”
预训练后的模型,就像刚毕业的大学生:懂很多知识,但不知道怎么 “用”。后训练就是让它 “实习”,学会对齐人类的指令和价值观,比如 “说有用的话、不说有害的话”。
后训练主要有两种方法:
- 监督微调(SFT):
相当于 “师傅带徒弟”。用人工标注的 “指令 - 答案” 数据教模型 —— 比如 “用户说‘送货慢’,要回复‘抱歉,我们会加急处理’”,让模型学会特定任务的处理方式。 - 强化学习(RLHF)相当于 “靠反馈改错”。让模型生成多个答案,人类或奖励模型给这些答案打分(好 / 坏),模型再根据分数调整 —— 就像你写方案被领导打回修改,多改几次就知道怎么写符合要求了。
- OpenAI 的 GPT 系列:先预训练,再 SFT,然后训练奖励模型,最后用 PPO 算法循环几千次优化 —— 一步步打磨到 “听话”。
- DeepSeek 更 “激进”:直接跳过 SFT 阶段,把 RL 用到基础模型上,还换了 GRPO 算法替代 PPO,内存开销降了 50%—— 相当于 “天赋高的学生,不用专项辅导,直接实战就能进步”。
这里给产品人提个醒:选模型时,别只看参数大小,还要看后训练方法 —— 比如做企业私有化部署,DeepSeek 这种 “高效训练” 的模型,成本会低很多。
三、大模型的 “记忆” 和 “表达”:为什么有时会 “胡说八道”?
做客服 AI 时,最头疼的就是模型 “一本正经地胡说八道”—— 比如用户问 “我们公司的退货地址在哪”,它编了一个不存在的地址,还说得有模有样。后来才明白,大模型根本不是 “记住” 了知识,而是靠 “概率” 生成回答。
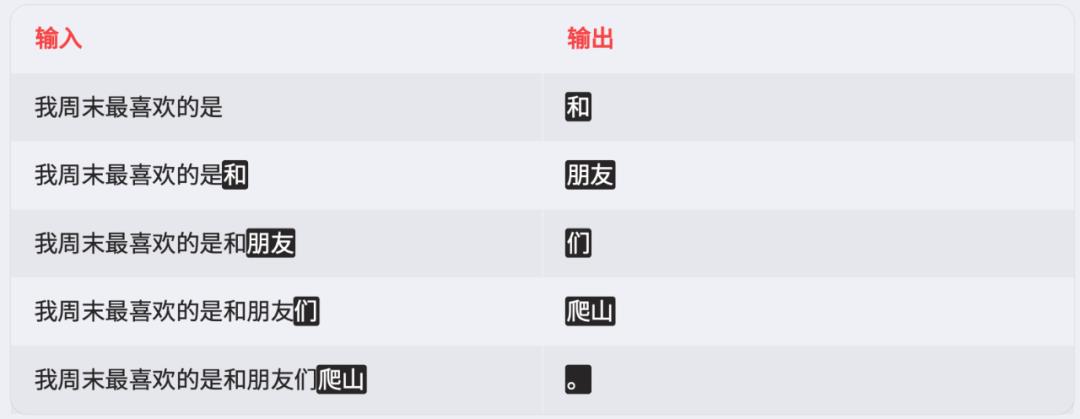
它的记忆方式很特别:不是像人类一样记 “事实”,而是记 “字词组合的概率”。比如训练数据里,“退货” 和 “7 天内”“未拆封” 一起出现的概率高,模型就会在回答时优先组合这些词。这些概率藏在 “模型参数” 里,参数越多,能存的概率信息越全。之前我们把模型参数从 7B 升到 34B 后,发现它很少再说 “退货需要 10 天” 这种错误答案,就是因为更多参数记住了正确的概率组合。而它的回答过程,叫 “推理”,本质是 “逐字猜”。比如用户输入 “我周末最喜欢”,模型先猜下一个词可能是 “和”,再猜 “朋友”,接着 “爬山”,一步步生成句子。“和朋友” 的概率是 85%,“和家人” 是 10%,所以模型优先选前者。但这种 “猜” 也会出错,比如用户问 “2024 年我们公司的新退货政策”,模型没学过 2024 年的数据,就会把 2023 年的政策 “套” 进去,甚至编一个,这就是 “幻觉” 的由来。之前我们解决这个问题,是在提示词里加了一句 “不知道的话就说‘暂无相关信息’”,但效果一般。后来我们加了 “RAG”(检索增强),让模型先查我们公司的最新政策文档,再回答,幻觉率直接降了 40%。比如做长文本总结(如合同分析),选 Claude 比 GPT-4o 更合适;做中文短视频脚本,豆包比国外模型更接地气;如果要独立部署,DeepSeek 的开源版性价比很高。如果用开源模型,一定要做 SFT,比如我们给模型喂了自己公司的客服话术,用户反馈 “像真人” 的比例从 30% 升到 65%。如果是闭源模型(如 GPT-4),可以用提示词工程补场景知识,比如在提示词里写 “你是 XX 公司的客服,回答需包含‘7 天无理由退货’‘未拆封’等关键词”。比如模型数学差,就加计算器插件;记不住新信息,就加 RAG;怕幻觉,就加事实校验步骤。其实做 AI 产品这几年,我最大的感受是:大模型不是万能的神,而是个 “需要引导的学霸”。它有自己的强项(写文案、编程、问答),也有弱项(算数学、记新信息),我们要做的不是 “逼它全能”,而是 “用对它的优势”。比如下次你想做一个 AI 产品,不妨先问自己三个问题:这个场景需要模型 “懂语言” 吗?需要多大参数的模型才够?要不要用 RAG 或插件补短板?想清楚这些,比盲目跟风 “上大模型” 要有用得多。