线索要做质量打分和画像。 销售要做画像。 通过两边的智能打分和画像做匹配。
好线索分给好销售。 考虑销售状态,以及工作饱和度。 要给新人成长机会。
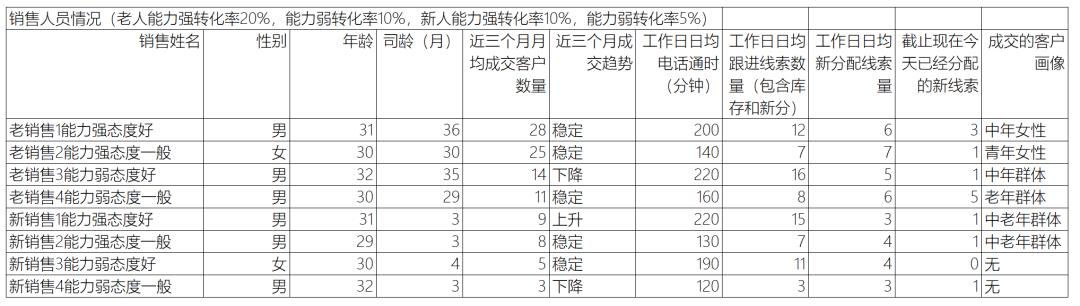
销售要分为新人和老人,两者区别很大; 从能力和态度两个维度进一步划分销售; 定义销售最近的工作状态,指出七业绩表现是稳定、上升还是下降; 老销售能力强,假定是指新客户转化率在20%左右; 老销售能力差,假定是指新客户转化率在10%; 新销售能力强,假定是指新客户转化率在10%左右; 新销售能力差,假定是指新客户转化率在5%; 工作态度好,假定是指日均电话通时在200分钟左右; 工作态度一般,假定是指日均电话通时在150分钟以内; 工作态度好,每日跟进的库存线索也会更多; 每个老销售都有自己擅长成交的客户画像,部分新销售这个标签缺失;
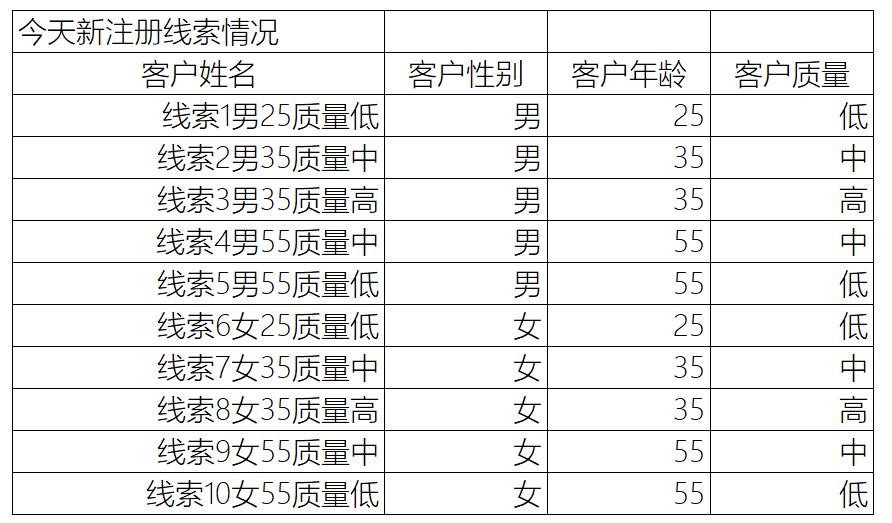
线索质量负责正态分布,高质量线索少,中低质量线索多; 线索质量假设已经按某个规则完成评分 评分规则不是本测试讨论要点; 线索提交时已经获取了性别和年龄信息;
你是一名销售团队的线索分配专家,需要将每天新注册的客户线索,合理的分配给合适的销售,以便帮助公司实现线索转化率的最大化。上边提供的是销售团队的人员信息,以及今天新分配的线索。请根据这些信息,将每个新线索分配给适合的销售,并给出理由。
接下来,就是大模型的表演时间,为了控制文章篇幅,让大家关注重点,每个大模型完整的深度思考过程我放在了本文的附录,接下来我挑一些要点进行分享。
大模型的智能分配逻辑
首先是能力匹配原则,让最有能力的销售处理最有价值的线索;
其次是客户画像匹配原则,尽量将客户分配给有相关成功经验的销售;
第三是工作量平衡原则,避免某些销售过于忙碌而另一些相对空闲;
最后是发展培养原则,给新人和表现较弱的销售适当的练手机会。
通过这样的精准分配,我们既能最大化高质量线索的转化率,又能促进整个团队的均衡发展,最终实现公司线索转化率的整体提升。
ChatGPT给出的分配原则:
根据每位销售员的能力和潜在客户的需求(如客户特征和销售人员的优势)来进行分类。
需要考量对客户感兴趣的特定能力,优秀的销售人员将被分配到高质量或难度较大的客户,而能力较弱的销售员将处理低质量或简单的客户。
我要根据销售人员的能力、态度和客户资料,例如年龄和性别,来分配客户。
为了合理分配,考虑到每位销售人员的客户偏好和能力限制,最后我为每个销售人员分配了合适的客户。
DeepSeek给出的分配原则:
客户画像匹配:优先将线索分配给其成交客户画像匹配的销售,因为销售更擅长转化特定群体(如年龄、性别)。 线索质量与销售能力匹配: 高质量线索(高):分配给能力强(月均成交客户数量高)且态度好的销售,以最大化转化机会。 中质量线索(中):分配给画像匹配的销售,能力中等或态度好的优先。 低质量线索(低):分配给能力弱但态度好的销售,因为他们更可能花时间努力跟进低转化率线索,避免浪费能力强销售的资源。 销售负载均衡:考虑销售的工作日日均新分配线索量和今天已分配的新线索,确保分配不超过其剩余处理能力(剩余能力 = 日均新分配线索量 - 今天已分配新线索)。如果剩余能力不足,则调整分配以避免超载。 其他因素:考虑销售成交趋势(稳定或上升优先)、电话通时(态度好的销售通时高)和跟进线索数量(努力程度)。新销售(司龄短)经验较少,但能力强的新销售可分配高质量线索。
腾讯混元给出的分配原则:
销售能力与态度:优先分配高质量线索给能力强、成交经验丰富的销售;
客户画像匹配:线索的性别、年龄与销售历史成交客户画像强相关时优先分配;
线索质量分层:高质量线索分配给经验丰富、跟进效率高的销售;中低质量线索分配给时间充裕、跟进耐心的销售;
当前负载均衡:避免单个销售短时间内线索过载(参考日均跟进量)。
大模型的智能分配结果
接下来,直接给大家看下分配结果,我整理在了一张表格中:
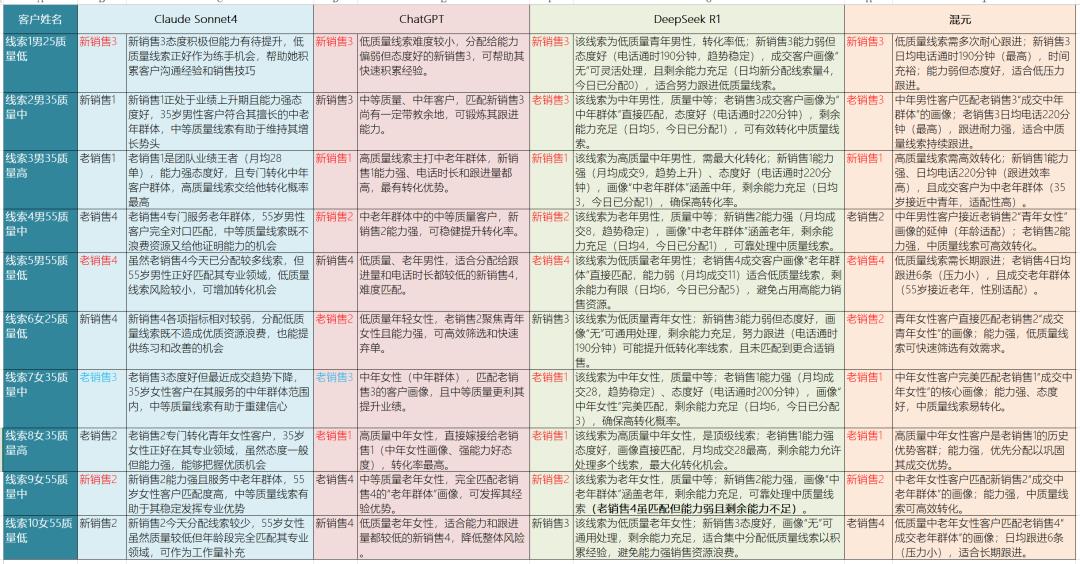
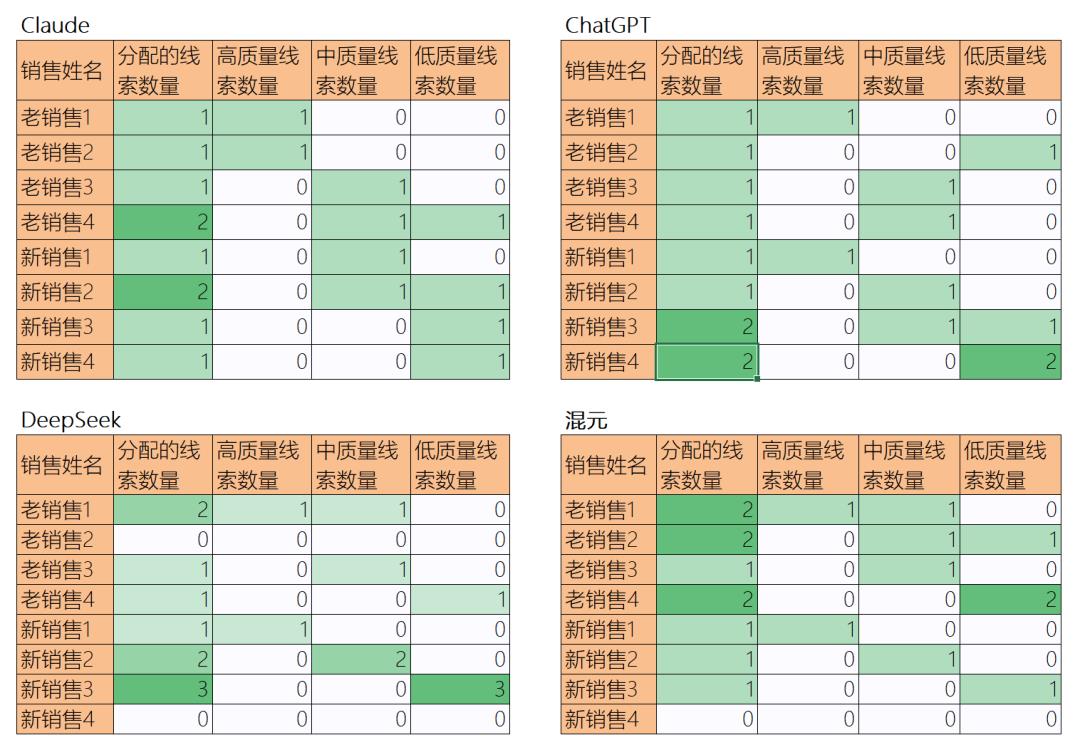
可以看到,对于每个线索,具体该分配给谁,每个大模型给出的答案都不完全相同,不过我还是对其中相通的答案进行了标记。
注意看,每一行,我将大模型分配结果一致的销售名字都标记了特殊颜色(主要是红色),例如,针对线索2,DeepSeek和混元都将他分给了老销售3,所以我标记为红色,而Claude将他分给了新销售1,ChatGPT将他分给了新销售3,所以各不相同,保留了黑色颜色。
这张分配结果图,读起来一定让你非常崩溃,因为里边的信息量太大,如果不是对实验数据有深刻的印象,估计也不太能准确捕获到这张图背后蕴含的结论。
为了方便我自己分析,也为了帮助大家理解,我让大模型进一步将分配结果做成了几张统计表,展示了针对不同销售,分别分配了多少个不同质量的线索,如下图:
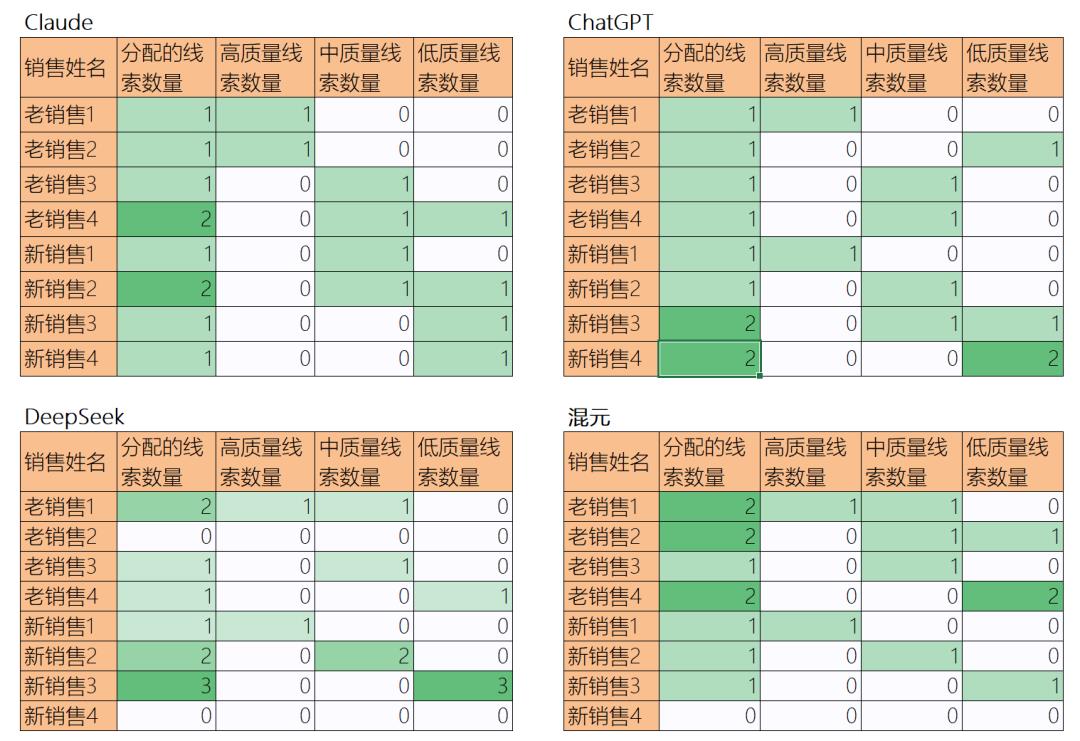
这张图相对容易阅读理解。
虽然图中会丢失很多细节逻辑,我结合自己仔细阅读了细致的分配逻辑,以及这张图,给大家总结下四个大模型的分配结果:
每个模型,基本上都把好线索所分给了老销售中的好销售;
最差的线索基本上都分给了新销售中的工作态度一般的销售;
有两个模型甚至给能力差、态度差的“新销售4”一个线索都没分配;
DeepSeek没有给老销售2分配线索,原因是从能力画像角度没有匹配到线索,DS决定再等等看看;
分配结果中唯一一个不合理的点:原数据中老销售4当日新分线索已经接近饱和,但是四个大模型基于线索画像和销售能力画像的匹配角度,依然给他分配了一到两个新线索,理由都是考虑到该线索由他转化更合适;但其实老销售4的身份假定是能力弱态度又一般,现实中不太可能给这类人很多线索,如果线索资源紧张,甚至不会给他线索,而大模型显然“心软了”,不过我觉得通过明确规则描述,这个问题很容易解决的。
整体来看四个模型分配的结果都可圈可点,符合我自己的经验认知,非要比个高低的话,我更喜欢Claude和DeepSeek的分配结果,平衡性更好,当然DeepSeek居然给两个两个销售一个线索都没分配,不过也给出了自己的合理解释,认为目前没发现匹配线索,虽然两个销售当天工作量有剩余,但可以等等看后续会不会有更合适的,这个理由我觉得是可以接受的。Claude甚至还说,从发展培养的角度,要给态度良好能力一般的新销售更多差线索,以便其学习成长,这些认知着实让人惊喜。
实验总结和感想
说实话我之前对大模型在企业业务流程自动化的应用是持有严重的怀疑态度,但实际体验下来,我认为AI真的很聪明,给出的逻辑,已经能帮助很多团队落地实践并且提效了。
当然大模型本质上还是基于思维链的推理逻辑在完成策略,而人工智能本身还包括深度学习神经网络算法等更多黑盒逻辑,某些业务场景可能更适合采用后者。
但不论怎样,经过实际动手实践,大模型的能力还是让我很震惊,也让我发现自己之前主观的短视和狭隘的眼光是多么的幼稚。
看来,年纪大了,总会被自己的固有认知局限住,我们这些老年人,一定要虚心接纳新事物啊!
PS:四个大模型的推理过程内容太多太长了,如果你想看具体的推理过程,以及文中Excel源文件,可以加我微信,我单独发给你。