导读:推荐的过程,本质上就是将人和物高效match的过程,这个过程就类似于红娘如何将2个本不认识的人最终撮合在一起。同时,从信息获取的视角来看,推荐也是一种信息过滤系统,它帮助人们可以更快更准的获取信息
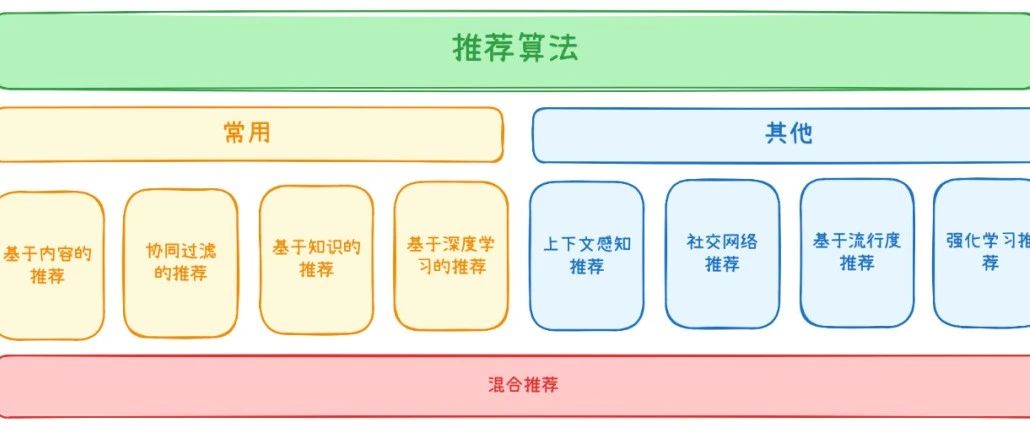
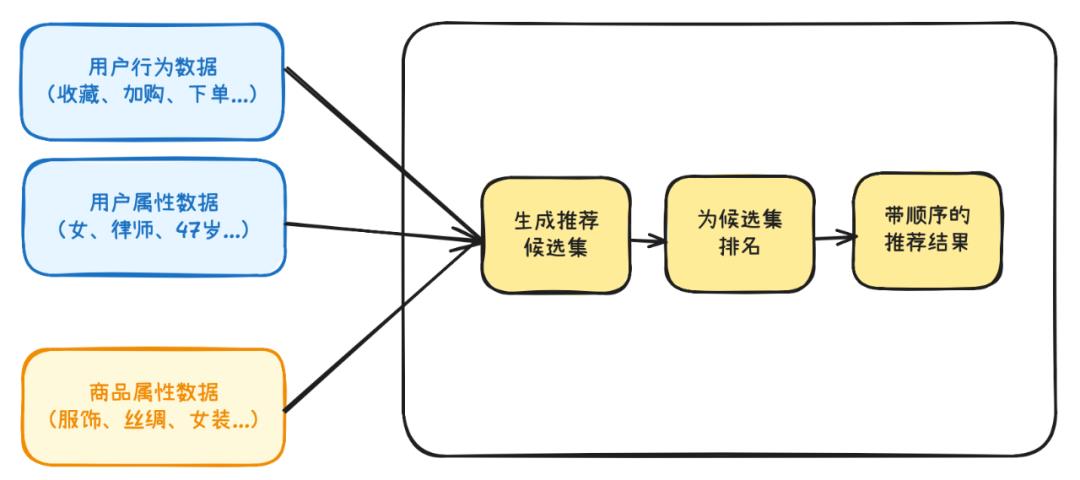
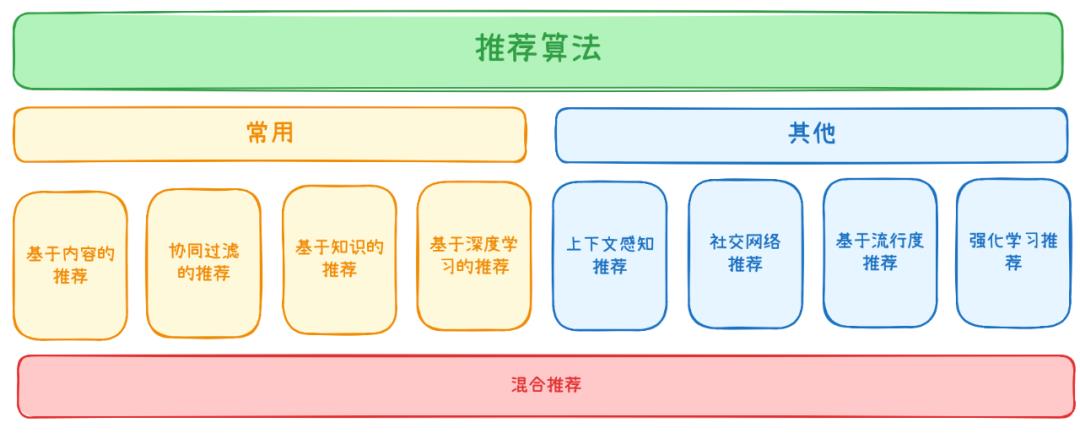
推荐的过程,本质上就是将人和物(这里的物是泛指,包含内容、商品等任何需要进行匹配的对象)高效match的过程,这个过程就类似于红娘如何将2个本不认识的人最终撮合在一起。同时,从信息获取的视角来看,推荐也是一种信息过滤系统,它帮助人们可以更快更准的获取信息。从结果来看,最终生成的肯定是针对某个(某类)人的物品推荐列表,同时,这个列表是有先后顺序的。那么,推荐系统的最基础架构就如下图所示:1、数据:算法的基础就是要有数据,同时我们也是用来将人和物进行匹配的,自然就需要用户和商品2类数据。在原始属性数据之上,还新增了用户的「行为数据」,其实这也是近几年算法应用的核心点——即在移动互联网兴起之后,通过用户在屏幕上的行为事实(点赞、停留、收藏、加入购物车、下单、转发、评论等)去更近一步挖掘偏好和进行推荐。2、粗筛:先快速过滤出一批候选集来提升效率。想象当我们打开淘宝时,后台估计有上亿个SKU(商品的基本单位),如果算法挨个去计算和我的匹配度,那估计等一天都计算不完;而初筛则是快速筛出来1000个商品(数量可自定义),这样再去算这些商品和用户的匹配度就会更高效。3、排序:最后就是给这1000个商品按照匹配度进行排序了。匹配度越高排名就越靠前,例如,现在是夏天,最近我买了好几条裙子,自然它就会优先推荐裙子而不是裤子。在了解推荐系统大概是怎么回事之后,我们来详细看看算法到底是按照什么样的逻辑来计算和进行推荐的。推荐算法分为以下几类:基于内容的推荐、协调过滤推荐、基于模型的推荐、基于知识的推荐、基于深度学习的推荐、混合推荐、上下文感知推荐、社交网络推荐、基于流行度推荐等。其中黄色部分为较常用的推荐算法,同时,混合推荐则是将多种算法进行结合来弥补单一算法不足的一种处理方式。- 基于内容的推荐:这是一种较为入门的推荐方法,即分析用户历史行为或偏好,提取项目的内容特征,推荐与用户偏好相似的项目。例如,你过去爱看《夏洛特烦恼》这一类喜剧片,则继续给你推荐《西虹市首富》这一类喜剧片。
- 协同过滤的推荐:通过用户与物品的交互行为来挖掘相似性进行推荐。例如,和你一样画像(年纪、性别、喜好相仿)的小李喜欢听《七里香》,那系统则认为你也大概率会喜欢听《七里香》。
- 基于知识的推荐:利用业务领域的知识和用户需求等进行规则式推荐。例如,在冷启动阶段,用户输入预算和户型需求,来推荐符合要求的房源。
- 基于深度学习的推荐:利用神经网络自动捕捉用户-物品之间的特征规律,从而找出更佳推荐结果。例如,神经网络自动学习历史数据后,发现「一线城市、女性、白领」对「200元较贵的香薰」更有偏好性。
- 上下文感知的推荐:结合时间、地点、场景等上下文信息进行推荐。例如,在下雨天,系统推荐步行少和优先打车的通行方案。
- 社交网络推荐:利用用户社交关系进行推荐。例如,你的好友小王也点赞了某篇小红书文章,那么,系统也会为你推荐该内容。
- 基于流行度的推荐:推荐热门内容和物品,常用于冷启动阶段。例如,最近很流行讨论孙俪董子健的热播剧《蛮好的人生》,即使我没看过,也逐渐在小红书碎片内容中刷完了整个剧情...
- 强化学习推荐:通过用户实时的动态交互来优化推荐策略。
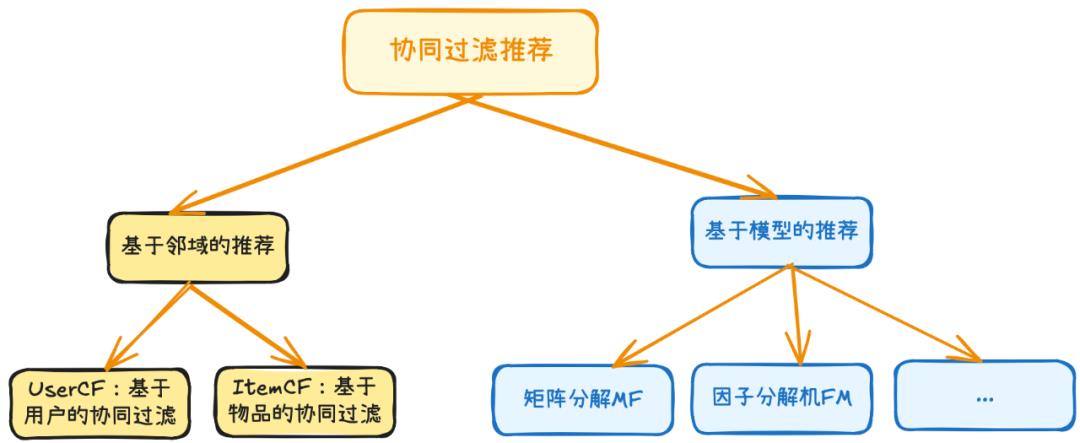
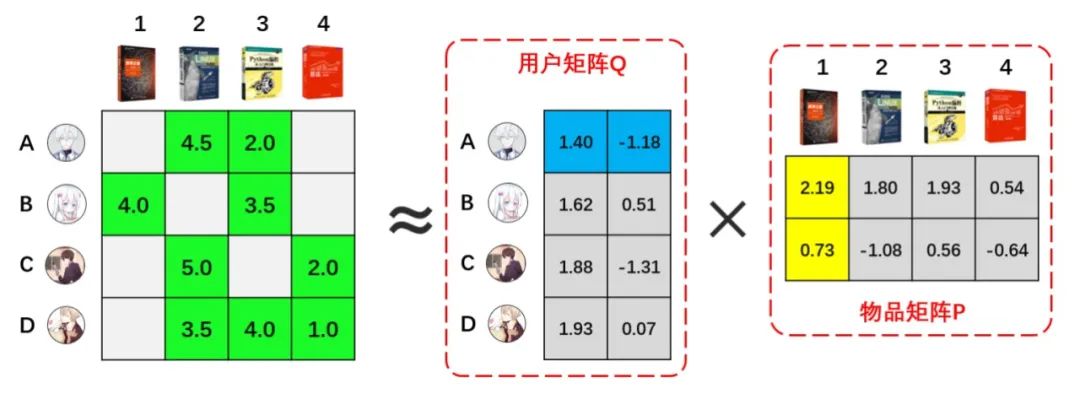
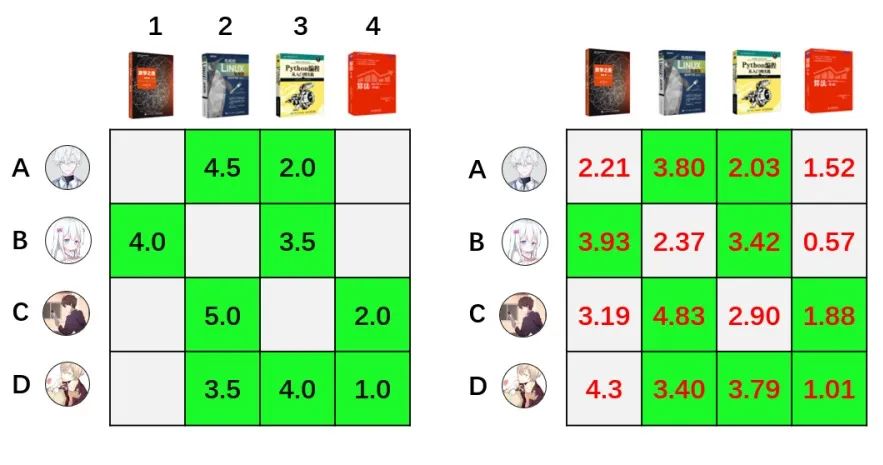
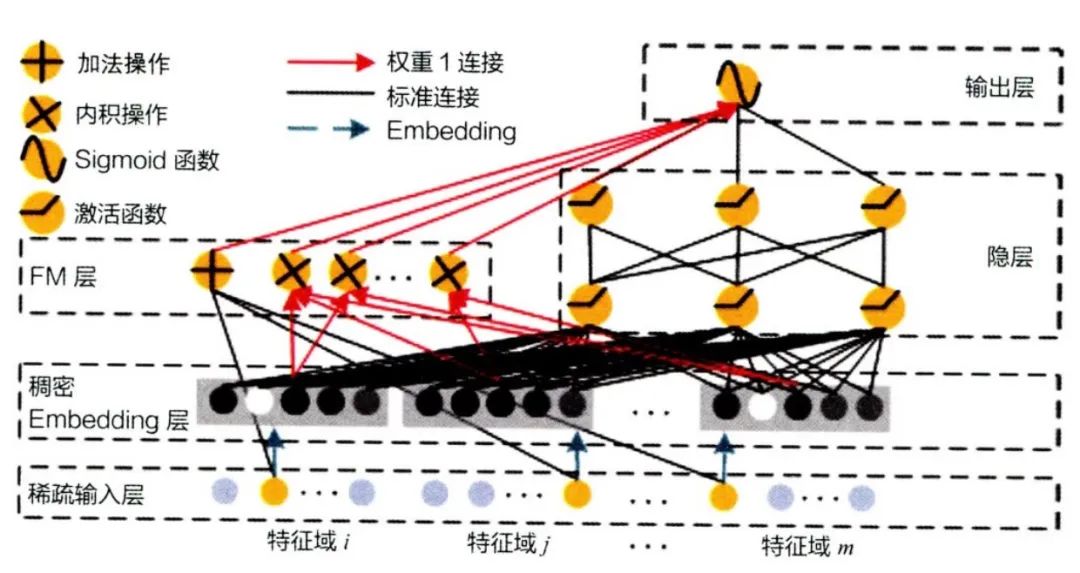
下面来重点针对其中主流且稍进阶的常见算法进一步展开:协同过滤=基于协同去做过滤,利用群体协同的智慧来做信息过滤。邻域推荐的假设前提为——人的偏好不容易变化,你喜欢文艺的内容、那么你大概率还会想看文艺的内容,这就是基于物品的协同过滤;你喜欢文艺的内容,那么和你很像的闺蜜也大概率喜欢文艺的内容,这则是基于用户的协同过滤。而基于模型的推荐,则指的是应用机器学习模型来自动挖掘用户和物品的潜在特征。这里我们展开补充2种常见的机器学习算法:矩阵分解、因子分解机。以下图为例,最左侧是一张用户原始的喜好表,其中A用户对图书2的喜好分为4.5分,对图书3为2.0分,但是它并没有对图书1和4的喜好打分。在日常实际数据中,数据往往大而稀疏,会出现非常多为空的数据。那么,矩阵分解算法通过计算,先将用户原始喜好表拆解为2个矩阵,该矩阵需要很好的拟合原始数据(此处忽略一堆复杂的数学计算过程):再将2个拆好的矩阵进行相乘,最终将空白处进行填补,这就预测出来了用户A对图书1和4的喜好偏好为2.21分和1.52分,评分越高则用户越喜欢。矩阵分解就像用户id和物品id的专属相亲大会,只能处理简单的用户和物品之间的关系,毕竟矩阵这种分解的形式本身也有其局限性;而因子分解机则更为进阶,它是全员参与的交叉配对联谊,可以挖掘出任意特征交叉的二阶交互,从而例如用户年龄x物品类别、天气x温度等。例如,我们有一张历史数据表,包含的字段有:用户id、商品id、用户年龄、商品类别、历史点击次数。因子分解机将自动建模和两两挖掘所有特征的二阶交互,例如用户idx商品id、用户年龄x商品类别(年轻人更爱电子产品)、历史点击x商品id(活跃用户偏好),最终综合了所有特征的交叉影响来预测用户对商品的点击概率。前面我们有矩阵分解和因子分解机(二阶特征交叉),那么,万一有一类用户是三阶特征交互下点击概率最高呢?这里,我们就引入DeepFM(基于深度学习的因子分解机)。DeepFM采用了FM+DNN(因子分解机+深度神经网络)的方式,既能考虑到低阶特征交互(1阶+2阶),又能考虑到高阶特征,最终综合性地挖掘出多阶的特征组合,从而更精准的进行推荐。首先,先对原始数据进行one hot编码的稀疏输入处理;之后,再对特征进行embedding向量化处理,后续,则是进入到了FM和DNN层处理(这块对我也是个黑盒,感兴趣大家可以自行了解),最终输出预测结果。基于深度学习的推荐算法还有wide&deep(既考虑到广度,也考虑到了深度)等等,其本质上都是应用了深度学习中的一些模型架构(如DNN)来提升预测效果,就不再展开了。回想一下我们在刷小红书、抖音等的时候,既能看到非常热门的一些动作手势舞视频,也偶尔会看到没什么人点赞的视频。这其实是最终企业要去权衡的点,匹配度算出来了,但该如何最终呈现内容是一个需要取舍的问题。只推荐匹配度高的问题,用户可能会看腻,同样,一些小众的新内容得不到推荐,最终形成一个恶性循环。所以,最终又回到了如何评估推荐系统效果的衡量指标上来,这个指标不止包含预测准确度,显然还要考虑多样性、实时性、商业目标等。