想构建一个像样的企业级AI应用?
你的技术栈可能长这样:用MySQL/PostgreSQL存元数据和业务数据,用Elasticsearch做关键词搜索,再搭个Milvus/Chroma管向量。
一个简单的查询,就得在三四个系统间反复横跳,写下成百上千行胶水代码来拼接、排序、保证数据同步。
这套弗兰肯斯坦式的架构,不仅运维复杂、成本高昂,更致命的是,数据延迟和不一致性让AI的智能大打折扣。
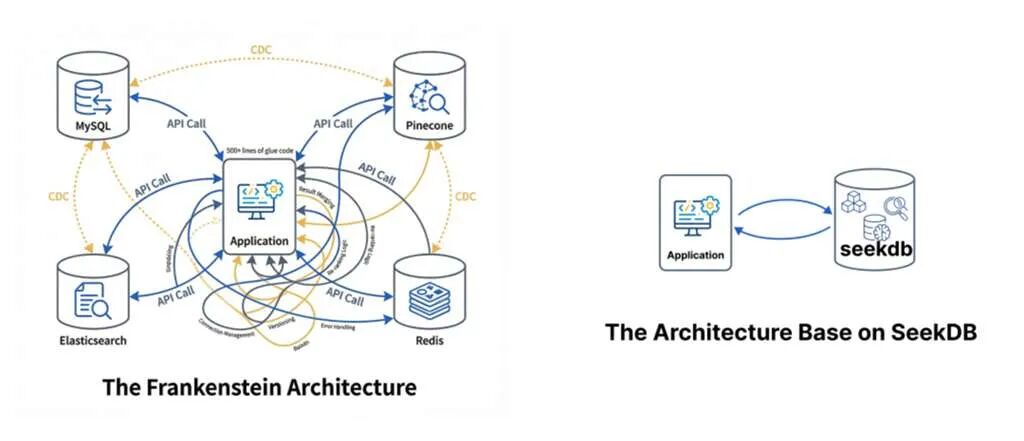
从复杂的弗兰肯斯坦架构到基于seekdb的极简架构
我们苦苦寻觅的,是一个能终结这场数据拼装困局的统一底座。
最近,蚂蚁集团旗下的OceanBase开源了一款名为OceanBase seekdb的产品,号称首款AI原生数据库。
在深度体验和研究后,我可以说,这可能就是我们一直在等待的答案。
AI数据库战国时代:为何需要新物种?
AI浪潮之下,数据库领域正上演一场范式跃迁。
为了给大模型提供记忆和知识,各种解决方案层出不穷,大致可分为三派:
向量数据库派(TheSpecialist):
以Milvus、Chroma、Pinecone为代表,专为向量相似度搜索而生。
它们在语义检索上表现出色,但处理结构化数据、事务和复杂SQL查询时力不从心,往往需要与传统数据库配合使用。
关系数据库扩展派(TheClassic):
以PostgreSQL+pgvector为代表。这种方案能在一个库里同时处理业务数据和向量,但本质上是外挂能力。
向量检索、全文检索和标量查询在底层是不同的优化路径,强行缝合的查询优化器难以做到全局最优,大规模场景下性能瓶颈明显。
搜索引擎派(TheSearchEngine):
以Elasticsearch(ES)为代表,ES在全文检索上是王者,近年来也加入了向量搜索能力。
但其底层设计终究是为搜索而非事务,数据一致性(ACID)保障较弱,不适合作为AI应用的核心业务数据存储。
这三种路径都未能完美解决问题,开发者依然要在多个数据孤岛间奔波,忍受着数据同步延迟、权限策略割裂、运维复杂度飙升的痛苦。
我们需要一个新物种,它既要有关系型数据库的严谨与全面,又要有向量数据库的语义理解能力,还要有搜索引擎的关键词匹配能力,并且将这一切原生融合在一个引擎内。
混合搜索为何是灵魂?
大模型的强大在于推理,但其短板在于缺乏长期记忆和对实时、私有知识的感知。
RAG(检索增强生成)和Agentic AI的核心,正是通过上下文工程(Context Engineering)为模型提供精准、实时的养料。
一个高质量的上下文,绝非简单的找相似就能搞定。
想象一个真实的业务场景:
金融反欺诈:查找过去7天内,交易金额超过5万元、地理位置异常、且行为模式与历史欺诈样本相似的账户。
这个需求包含了三种查询类型:
结构化过滤(Scalar Filter):过去7天、交易金额>5万元
关键词/地理空间匹配(Keyword/GIS Match):地理位置异常
向量语义搜索(Vector Search):行为模式与历史欺诈样本相似
单一的向量搜索或全文检索都无法独立完成这个任务。
只有将这三种能力融合在一起的混合搜索(Hybrid Search),才能在一次查询中精准锁定目标。
这正是AI数据库的核心能力分水岭,也是从AIReady迈向AINative的关键一步。
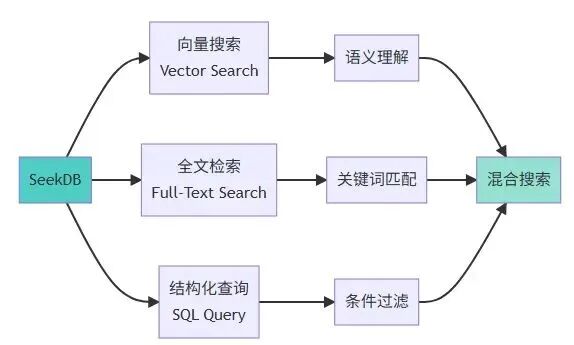
混合搜索融合了向量搜索、全文检索和结构化查询
一体化基因:当TP/AP遇上AI
提到OceanBase,很多人的第一印象是金融级的分布式数据库,以其强大的HTAP(混合事务/分析处理)能力和在TPC-C、TPC-H测试中登顶的性能而闻名。
这种一体化基因,在AI时代被赋予了新的价值。
TP+AI:实时一致的上下文
传统RAG架构中,业务数据库(TP系统)的数据变更需要通过CDC(ChangeDataCapture)工具同步到向量库和搜索引擎,这个过程存在分钟级甚至更长的延迟。
这意味着AIAgent获取的可能是过期的上下文,导致决策失误。
而OceanBase的一体化架构,凭借其成熟的事务引擎和Multi-Paxos协议,保证了数据写入的强一致性(ACID)。
当数据发生DML(增删改)操作时,标量、向量、全文索引同步更新,实时可查。这意味着AI应用获取的上下文永远是最新、最一致的,彻底消除了上下文腐烂问题。
AP+AI:为什么向量检索需要分析引擎?
很多开发者有个误区,认为AI应用只需要向量搜索。
但在真实的业务场景中,没有分析能力的AI,往往是盲目的。
我们来看一个真实的电商智能补货与推荐场景,你就能明白为什么OceanBase seekdb要把TP、AP和AI熔于一体:
当大促期间海量订单涌入(TP场景),系统不仅要保证库存扣减的强一致性,还需要实时决策:当下该给用户推荐什么?
单纯的AI视角(向量):可能会推荐和用户历史购买相似的商品。
单纯的AP视角(分析):可能会推荐当前销量榜Top10的商品。
但在OceanBase的一体化架构中,这两个视角是原生融合的。
数据库内核可以在一次查询中完成以下复杂逻辑:
找出向量特征与用户画像相似(AI),且实时库存大于50(TP),同时过去1小时销量环比增长超过20%(AP)的商品。
在这个过程中,OceanBase的查询优化器(Optimizer)展现了其独特的价值,它不会像拼装架构那样,先从向量库捞出1万个相似商品,再扔到分析库里去过滤库存和销量(这会带来巨大的网络开销和延迟)。
相反,它会生成一个混合执行计划,利用AP引擎的列存能力快速筛选出热销且有货的商品集合,仅对这部分数据进行向量距离计算。
这就是一体化的威力。
数据零搬运:AI模型参数与AP中间结果共享内存池,没有跨系统的数据ETL。
决策实时化:从交易发生(TP),到报表分析(AP),再到AI推理(AI),全链路在毫秒级完成。
这不仅是功能的叠加,更是让AI具备了实时商业洞察力。
OceanBase正是基于这种理念,将TP的稳、AP的快与AI的智集成于单一内核,为OceanBase seekdb的诞生奠定了最坚实的底层地基。
深度拆解seekdb:AI原生是如何炼成的?
如果说OceanBase企业版是面向大型企业的航母,那么OceanBase seekdb就是OceanBase将其核心AI能力降维封装,为广大开发者量身打造的一艘轻快而强大的驱逐舰。
seekdb的设计理念正是为AI重构数据库,而非给数据库加AI。
它在一个轻量级的系统中,原生融合了向量搜索、全文检索、结构化查询、ACID事务和AI函数能力。
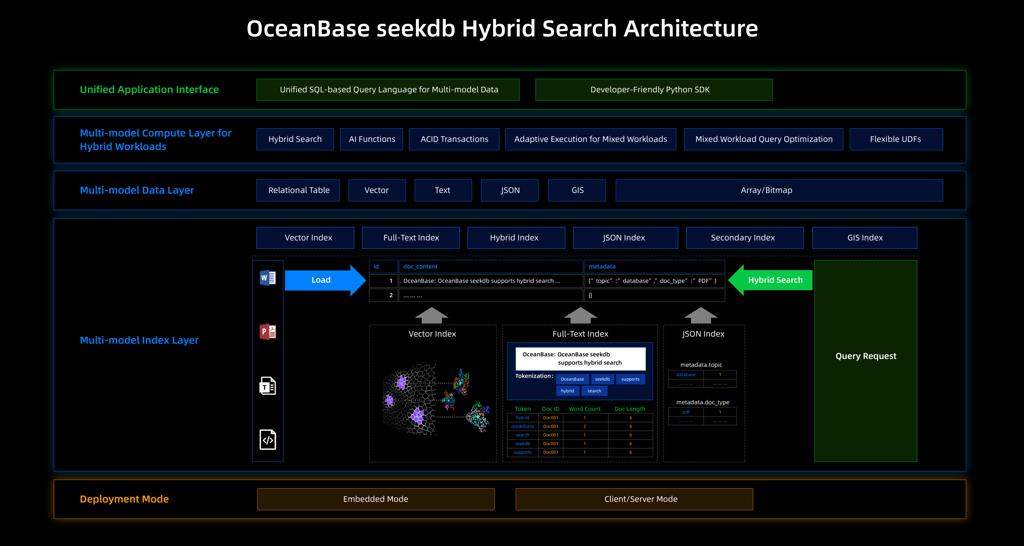
OceanBaseseekdb混合搜索技术架构
技术架构:源于OceanBase,专为AI
seekdb的架构继承了OceanBase成熟的单机引擎,并针对AI场景进行了深度优化:
全面开源的魄力
在数据库领域,开源协议的选择往往决定了其社区生态的未来。
seekdb从第一天起就选择了Apache2.0协议进行全面开源,这无疑向全球开发者社区释放了最大的善意和诚意。

Apache2.0意味着开发者可以自由地使用、修改、分发,甚至进行商业化,而没有类似AGPL/SSPL等协议带来的传染性风险。
这使得seekdb不仅对个人开发者和初创公司极具吸引力,也让大型企业可以放心将其集成到自己的产品中。
除了seekdb本身,OceanBase还同步开源了两个重要的生态组件:
PowerRAG:
基于RAGFlow二次开发的企业级智能文档解析框架,支持多模态内容处理和高质量检索。
PowerMem:
AI记忆引擎,用于解决大模型的长期记忆问题。它在权威的LOCOMO评测中以73.51分的成绩位列全球第一,并且能将Token消耗降低高达94%,显著节省推理成本。
OceanBase seekdb+PowerRAG+PowerMem形成了一套完整的AI数据基础设施,这展现了OceanBase不仅仅是提供一个数据库,而是希望与全球开发者共建一个繁荣的AI应用生态的决心。
这是一种从卖产品到建生态的战略跃迁。
轻量化为开发者和中小企业减负
对于广大开发者和初创团队而言,再强大的功能如果部署门槛高、资源消耗大,也只能是屠龙之技。
OceanBase seekdb最让我惊喜的一点,就是它的极致轻量化。
极简部署与超低资源占用
最低配置:
仅需1核CPU、2GB内存即可运行,甚至可以在此配置上跑通VectorDBBench基准测试。
一键安装:
支持pipinstall oceanbase-seekdb一键安装,秒级启动。对于习惯了Python生态的AI开发者来说,这体验简直不要太友好。
双模式部署:
支持嵌入式(作为Python库集成到应用中)和客户端/服务器两种模式,覆盖了从本地开发、边缘设备到线上服务的所有场景。
谁更胜一筹?
我们将seekdb与市面上主流的AI数据库方案进行一个全方位的对比:
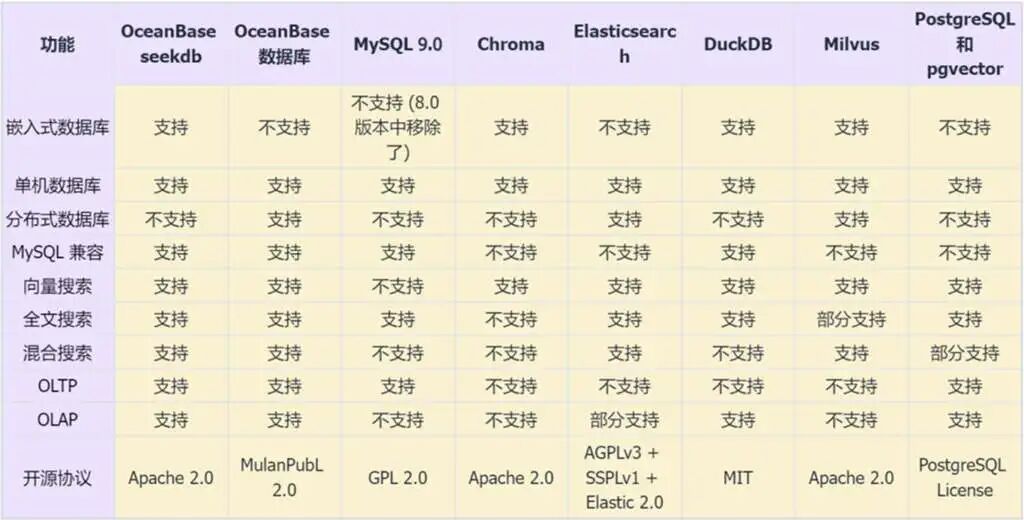
从上表可以看出,OceanBase seekdb是唯一一个同时在嵌入式、MySQL兼容、混合搜索、OLTP、OLAP等多个关键特性上都打勾的产品。
它填补了市场的空白,既有SQLite的轻量便捷,又有Milvus的向量能力,还兼具ES的全文搜索和MySQL的事务与SQL能力。
性能与成本优势
根据VectorDBBench的社区测试数据,在多个数据集和并发场景下,Milvus整体性能表现优异,而Qdrant在低延迟和过滤查询上表现不错,Chroma则更适合小规模实验。
OceanBase seekdb源于经过TPC-C和TPC-H双重考验的OceanBase引擎,其性能底蕴深厚,尤其在混合负载和实时写入场景下具备天然优势。
如果我们将视角拉高,从架构层面审视TCO,OceanBase seekdb的一体化架构特性带来了运维成本的断崖式下降。

OceanBase seekdb的性价比不仅仅体现在免费开源和轻量化部署上,更体现在它为 AI 应用提供了一种极简架构。
它用1/3的存储空间、1/N的运维精力、以及节省96%的Token成本,换来了更实时、更一致的AI体验。
采用seekdb这样的一体化方案,意味着你可以省去维护多个数据库系统的运维成本、数据同步链路的开发和维护成本,以及跨系统调用带来的性能损耗。
对于资源有限的团队来说,这笔账算下来,节省的不仅仅是金钱,更是宝贵的开发时间。
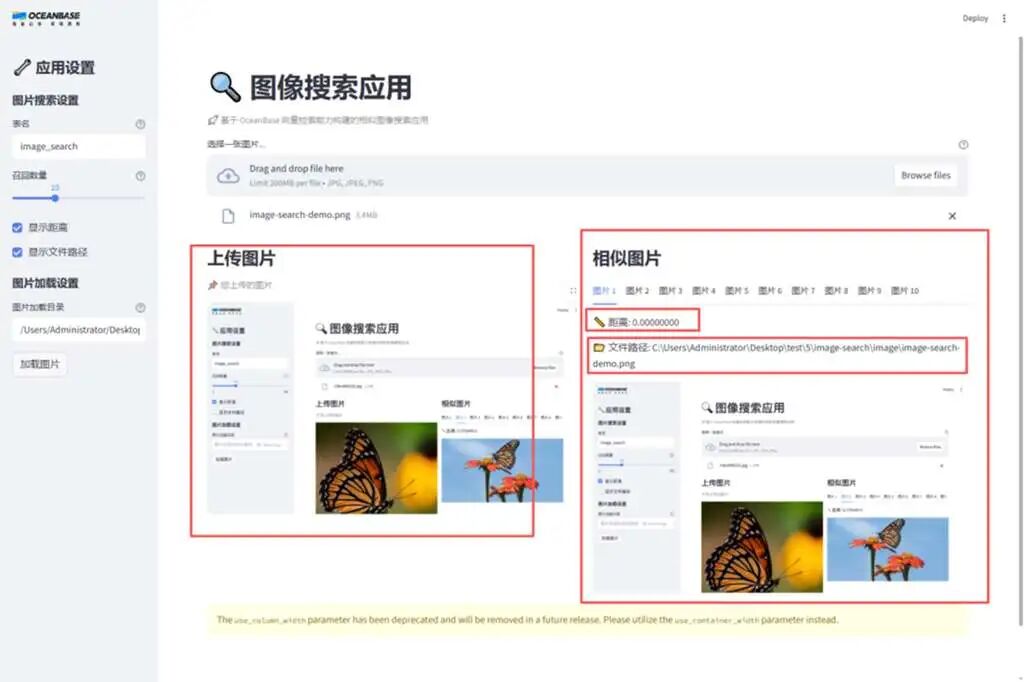
基于seekdb构建的图搜图应用界面
这张图展示了seekdb的轻量化部署和混合搜索能力。
它将图片向量化、存储、检索等复杂流程封装在底层,开发者只需关注应用逻辑本身。
AI数据库的终极形态
AI时代的数据库竞争,正从支撑业务转向驱动智能。
未来的数据库,不仅要服务于人,更要服务于智能体。
不仅要存储数据,更要理解数据、融合多模信息、实时赋能推理。
OceanBase seekdb的出现,清晰地验证了这一方向。
它不是又一个单纯的向量数据库,也不是传统数据库的修修补补,而是一个真正为AI应用而重构的、集大成者。
它的独特优势在于:
原生融合:
在单一引擎内实现了向量、全文、标量查询与事务处理的无缝融合。
极致轻量:
将企业级的强大能力下放到个人开发者可轻松驾驭的级别。
全面开源:
以最开放的姿态拥抱全球开发者,共建生态。
在这个AI日新月异的时代,选择正确的工具,意味着事半功倍。
如果你还在为搭建复杂的AI数据管道而烦恼,如果你正在寻找一款能够简化开发、降低成本、同时又具备强大性能和未来扩展性的数据库,那么OceanBase seekdb绝对值得你花时间去了解和尝试。
AI时代的真正护城河,不在模型参数,而在那个能高效、实时、可信地连接模型与数据的一体化数据引擎。
对于正在构建RAG、Agent或本地AI应用的开发者来说,无需复杂的Docker Compose,只需三行代码,你就能拥有一个企业级内核的AI原生数据库。
立即体验OceanBase seekdb: