方案:如何构建一个“行业人员库”数据产品

构建一个行业人员库数据产品,核心是围绕特定行业的人员特征、需求场景和数据特性,打造兼具“数据全面性、更新及时性、功能针对性、合规安全性” 的工具。
其本质是通过数据整合与价值挖掘,解决行业内 “人员信息分散、人才匹配低效、行业趋势难洞察” 等问题。
以下是具体构建步骤:
一、明确产品定位与核心目标
行业人员库与通用人才库的核心差异在于“行业聚焦”,需先明确三大核心问题:
1. 服务对象是谁?
? B 端
企业 HR(招聘、竞品人才分析)、猎头(精准挖人)、行业研究机构(人才趋势报告)、行业协会(会员管理)、投资机构(标的公司团队背景调研)。
? C 端(可选)
行业从业者(个人职业档案管理、同行连接)。
2. 解决什么核心需求?
例:
? 医疗行业
帮药企快速找到有临床试验经验的医生 / 研究员;
? 新能源行业
追踪电池研发领域的核心技术人员流动;
? 法律行业
检索某领域(如知识产权)的资深律师及胜诉案例。
3. 行业范围如何界定?
是“全行业”(如 “互联网行业人员库”)?
还是 “细分领域”(如 “互联网行业 - 自动驾驶算法工程师库”)?
初期建议从细分领域切入(降低数据采集难度,提升精准度)。
二、设计数据采集体系:覆盖“静态 + 动态” 全维度
行业人员数据的核心价值在于“全面性” 和 “动态性”,需构建多渠道、多类型的采集体系:
1. 数据维度设计(按 “人员价值” 分层)
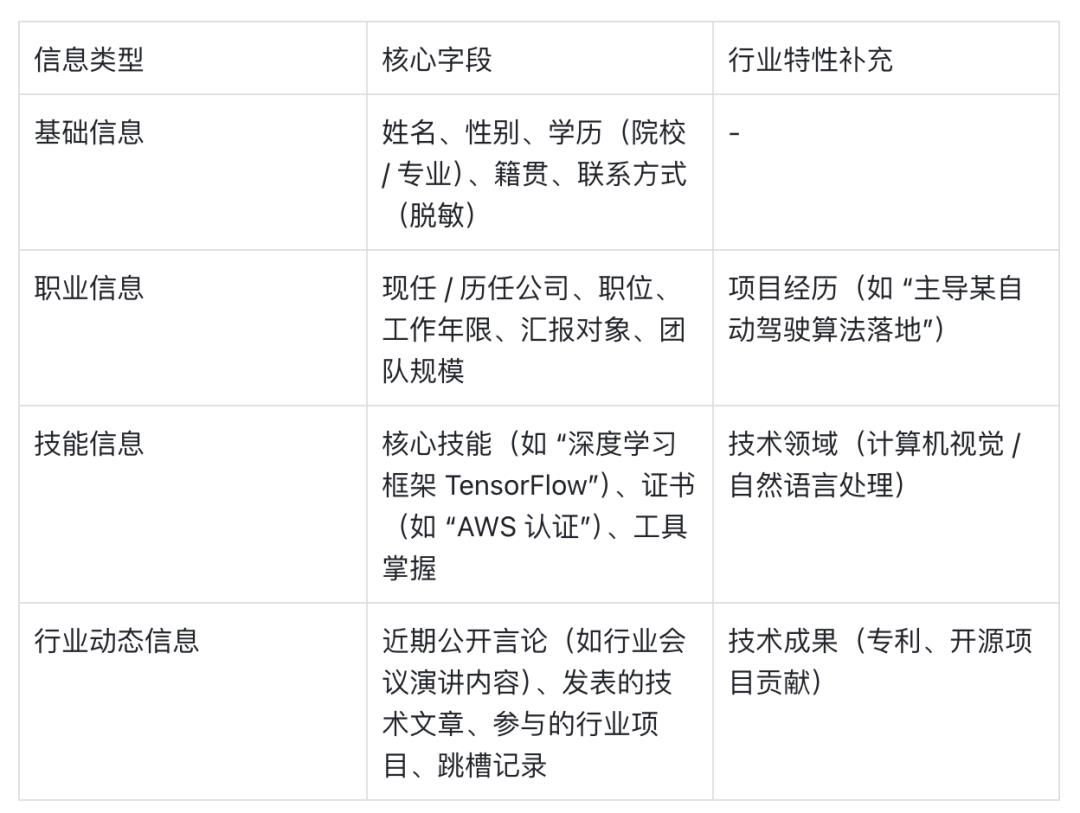
需覆盖“基础信息 + 职业信息 + 行业特性信息”,以 “互联网行业 - 人工智能工程师” 为例:
2. 数据来源渠道(兼顾 “公开 + 合作 + UGC”)
• 公开渠道(低成本但需清洗)
? 职业社交平台
脉脉、LinkedIn、领英行业页面、GitHub(技术类人员)、知乎 / 行业论坛(如医学论坛 “丁香园”);
? 企业端
公司官网“团队介绍”、上市公司年报 “核心成员”、企业招聘页(岗位需求反推在职人员技能);
? 行业活动
行业峰会嘉宾名单、学术会议论文作者、展会参展商团队信息;
? 媒体内容
行业媒体报道(如“某公司 CTO 接受采访”)、自媒体账号(如公众号 / 抖音的行业 KOL)。
• 合作渠道(高质量但需资源置换)
? 行业协会 / 联盟
如中国互联网协会、中国医师协会,获取会员名单及资质信息;
? 垂直机构
行业培训机构(如 IT 培训的学员就业数据)、猎头公司(脱敏后的人才库)、行业展会主办方(参展企业人员信息);
? 企业合作
与行业头部企业达成数据共享(如交换非敏感的人员技能分布数据)。
• UGC 补充
开放个人注册入口,用户自主填写 / 完善信息(如上传简历、更新职业动态),通过 “查看同行信息”“行业报告下载” 等权益激励主动录入。
三、数据处理:从“原始数据” 到 “结构化资产”
采集的原始数据多为非结构化(如简历文本、论坛帖子、PDF 论文),需通过 “清洗 - 结构化 - 标签化” 转化为可用资产:
1. 数据清洗:确保 “准”
• 去重
同一人可能在多平台有信息(如“张三” 在脉脉和 LinkedIn 的账号),通过 “姓名 + 公司 + 职位”“邮箱前缀”“手机号哈希值” 等唯一标识匹配去重;
• 纠错
修正错误信息(如“某公司名称写错”“职位年限计算错误”);
• 脱敏
对手机号、身份证号等敏感信息进行加密(如 MD5 哈希),仅保留必要的公开信息(如职位、公司)。
2. 结构化与标签体系:让数据 “可检索、可分析”
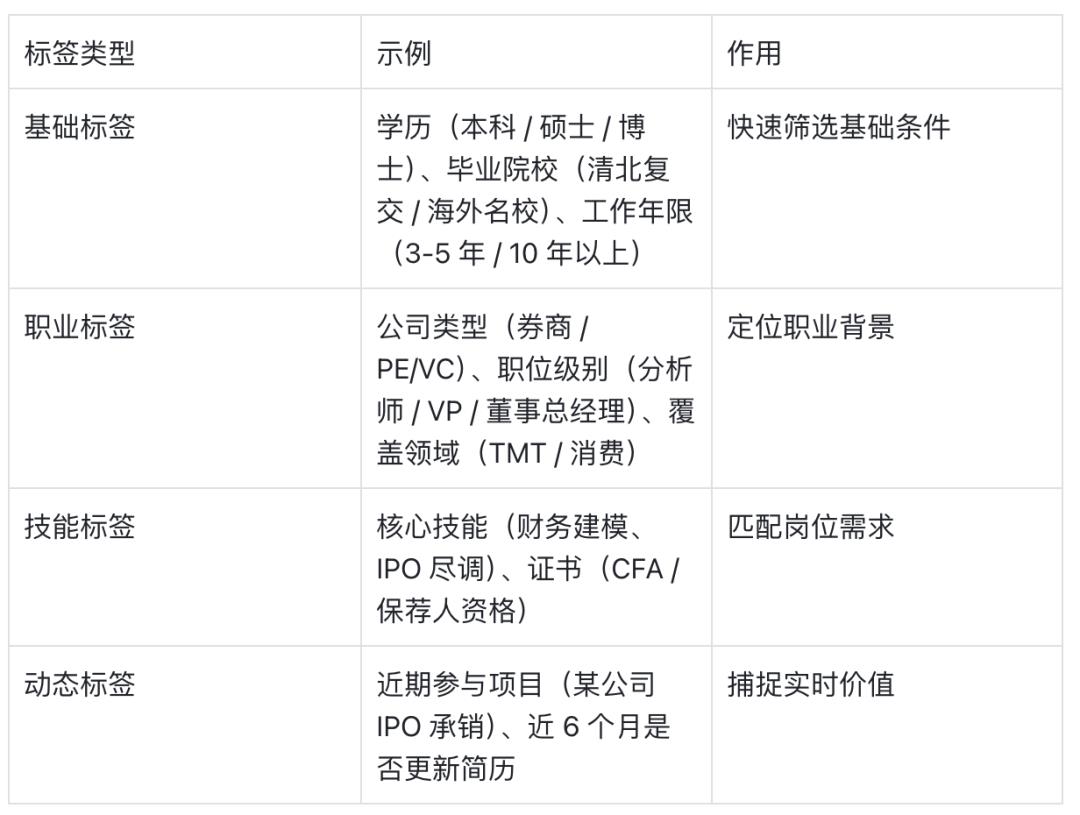
核心是建立行业专属标签体系,标签需满足“多维度、可扩展”,以 “金融行业 - 投行人员” 为例:
标签生成可结合“规则引擎 + AI 提取”:
• 规则引擎
如“持有保荐人资格证→标签:投行 - 保荐业务”;
• NLP 提取
从项目描述(如 “主导某消费企业港股上市”)中提取 “港股上市”“消费行业” 等标签;
• 人工校验
对高价值人员(如行业 KOL)的标签进行人工审核,确保准确性。
四、核心功能设计:聚焦“行业场景化需求”
功能需跳出“单纯检索” 的基础逻辑,结合行业特性设计 “高价值场景”:
1. 基础功能:解决 “找得到”
• 精准检索
多维度筛选(支持标签组合,如“新能源行业 + 电池研发 + 工作 8 年以上 + 曾任职宁德时代”);
• 相似推荐
输入某标杆人员(如“某车企首席电池科学家”),推荐背景相似的人员;
• 人才档案
聚合个人全维度信息(基础信息 + 职业轨迹 + 技能标签 + 动态记录),生成可视化档案页。
2. 行业特色功能:解决 “用得好”
• 人才地图
可视化展示行业人员分布(如“全国芯片设计工程师的城市分布”“某细分领域头部企业的核心团队架构”);
• 动态追踪
对目标人员的职业变动(跳槽、升职)、行业动态(发表文章、参会)设置提醒(如“某自动驾驶专家近期加入某初创公司”);
• 竞品分析
针对企业客户,生成“竞争对手人才结构报告”(如 “某竞品公司的研发人员学历占比、核心技能分布”);
• 行业趋势洞察
基于人员数据生成分析报告(如“近 3 年生物医药行业热门技能变化”“AI 行业人才流动方向:从大厂到初创公司”)。
五、技术架构:支撑“数据规模 + 响应速度”
• 前端:
Web 端(适配企业用户)+ 移动端(适配猎头 / 个人用户),重点优化检索页面的加载速度和筛选交互;
• 后端:
? 数据库
MySQL(存结构化标签、基础信息)+ MongoDB(存非结构化数据如简历原文、项目描述)+ Redis(缓存高频访问的人员数据,提升检索速度);
? 搜索引擎
Elasticsearch(支持复杂标签组合检索,响应时间控制在 1 秒内);
? 数据处理
Spark(批处理历史数据,如每日更新标签)+ Flink(流处理实时数据,如动态信息更新);
? AI 模块
部署 NLP 模型(标签提取)、推荐算法(相似人才推荐);
• 可视化
用 ECharts/Tableau 实现人才地图、趋势图表等可视化展示。
六、合规与安全:避免“踩坑”
行业人员库涉及大量个人信息,合规是生命线:
• 数据来源合规
公开信息需符合“合理使用” 原则(如不侵犯肖像权、隐私权);合作渠道需签署数据授权协议;UGC 信息需用户同意《隐私政策》;
• 数据使用合规
不向第三方泄露敏感信息(如手机号、住址);非公开信息(如未公开的跳槽意向)仅对授权用户开放;
• 存储安全
敏感数据加密存储(如身份证号、联系方式),定期做数据备份和安全审计;
• 地域合规
若涉及跨境数据(如行业包含海外人员),需符合《数据出境安全评估办法》。
七、冷启动与迭代:从“能用” 到 “好用”
1. 冷启动:
? 聚焦“小而美”
先做细分领域(如 “深圳 - 半导体设备研发人员库”),通过行业协会获取 1000 + 核心人员数据;
? 种子用户验证
邀请 3-5 家行业企业(如半导体设备公司 HR)试用,收集 “检索精度”“功能必要性” 等反馈;
2. 迭代优化:
? 数据端
根据用户需求补充缺失维度(如用户反馈“需要人员专利信息”,则增加专利数据库采集);
? 功能端
若猎头用户高频使用“动态提醒”,则优化提醒频率和触发条件(如 “仅提醒目标公司人员变动”);
? 商业化
根据用户类型设计付费模式(企业按账号付费、猎头按查询次数付费、研究机构按报告订阅付费)。
总结
行业人员库的核心竞争力在于“行业深度”—— 数据维度贴合行业特性、功能解决行业专属问题、数据质量(准确性 + 及时性)远超通用平台。