本文目录:
策略产品:从业务出发,用数据驱动
AI产品策略:模型能力调优和外围工程建设
产品经理重用户体验的要求早已稀松平常,今天来聊聊策略设计。
为什么要单独开一篇文章介绍?
一方面是现今产品同质化严重,同个领域的产品无论是产品核心流程、设计结构还是视觉风格,都殊途同归;另一方面,AI硬科技的浪潮下,仅从产品的外观表现你很难真正了解一款产品,产品的差异不再是多么花哨的视觉和别出心裁的交互体验,更多的是底层策略的高下之分。
回到今天的话题,我的论断是:大模型产品百花齐放的时代,产品策略的建设变得比过去更稀缺、更核心。究其原因,主要有以下几点:
首先是大模型产品的泛化能力,不再是即插即用,而要看你如何将特定的能力封装成产品功能。这近似是一个条件优化的问题:基于当前的大模型能力,找到一个最能产出价值的业务场景,选一个刚需、可控又能衡量ROI的点,先把这个点打穿。这个转化过程强依赖产品经理定义适用场景和约束边界;
当需求场景已经明确,用户体验和产品策略的设计都应该齐头并进。如果说,用户体验设计就像是在搭房子,比如设计房间布局、功能、装修风格;那么产品策略设计就是在建设水电气暖,让整个房子合理运转且节能高效。二者缺一不可。
1. 策略产品:从业务出发,用数据驱动
先来介绍下策略产品。
策略产品的本质是:基于数据和业务洞察,制定科学的产品策略,并通过数据体系、算法策略和能力封装,将这些策略落地为具体可执行的产品功能。
划重点:一个是从业务出发,一个是用数据驱动。

图1:策略产品的核心工作内容
举个例子,你在负责电商平台“猜你喜欢”的推荐策略优化,该模块的推荐点击率低,用户转化不佳,影响整体 GMV。
你的工作重心绕不开以下几点:
1)从业务出发,识别策略机会:
转化率低 → 用户推荐不精准 → 用户兴趣未被满足,将该问题转化为策略问题:如何让推荐结果更贴合用户兴趣?
为此你可能需要调整推荐优先级逻辑与召回策略。你可以定义目标场景与优先级:提升首页推荐点击率 + 后续转化率 → 优先攻关“高活跃用户 + 高客单价商品”场景。
2)以数据为驱动,设计底层数据体系:
输入数据:用户画像(性别、年龄、消费偏好)、浏览行为(近期点击、停留时长)、商品特征(品类、价格、促销力度); 输出指标:推荐点击率(CTR)、推荐转化率(CVR)、单位推荐位 GMV 贡献;
策略逻辑说明:比如,“猜你喜欢”优先展示用户最近3次浏览品类下的高转化商品; 交互设计:推荐位样式不变,后台策略调整,确保用户在交互时无感知; 后台配置能力:将数据指标经由数仓计算后落库,再通过策略运营平台下发,形成圈选用户的下发策略。
同理,产品经理在AI产品的策略设计中,也需要将业务场景转化为可落地的模型策略体系,包括策略设计、数据支撑、验证反馈与产品化,实现“业务目标→模型能力→产品形态”的完整链路。
2. AI 产品策略:模型能力的调优和外围工程的建设
除共性之外,说说AI 产品策略相较传统产品策略设计的核心区别。
仔细回想,原先所谓的产品策略更多是规则与数据驱动的产品设计范式,即:人制定策略规则+系统执行逻辑,比如:推荐策略、定价逻辑、排序规则、匹配机制、任务达标逻辑等。背后依赖的是:
结构化数据(标签、指标、用户行为等)
可解释的逻辑设计(if-then、权重模型、AB Test等)
可控可调的系统架构(策略平台、规则引擎、定时调度等)
而AI 产品改变了这套范式。
一方面,大模型引入了“能力即服务”。基座模型(如 GPT、Gemini、Claude)提供的是通用语言的理解+生成能力,系统不再依赖具体规则,而是:
从数据中学习模式(训练)
通过自然语言 prompt 驱动行为(提示)
通过外挂知识或模型微调提升上下文适应能力
底层范式转为:构建能力 → 套用能力 → 收集反馈 → 再强化能力。因此,算法团队需主导对基座模型进行预训练,产品经理则需要花更多精力在模型能力的调优上,比如模型微调,就是最常被考虑但最需要谨慎的行动点。
另一方面,策略设计由“显式逻辑”变成“能力配置”。传统策略的输入主要靠写规则、配权重,现在会更倾向于从设计提示词结构、配置知识库、判断模型是否微调逐层分析;而在策略的迭代调整上,传统产品以AB test为主调整策略,AI 产品依赖数据-反馈-能力多轮迭代去提升能力。
是的,当模型被训练完成后就拥有了通用和特定领域的知识和推理能力,但不一定能适配到特定的业务场景。大模型虽强,可天然是不稳定、不确定、不懂边界的,因此要围绕它建大量的工程体系来约束和监控它。
外围工程是什么?外围工程是指在不改变大模型本身参数和训练语料的前提下,通过外围能力增强模型的实用性和可靠性,从而更好地服务于垂直业务的需求。
换言之,真正把大模型从“能力”转化为“生产力”,就必须围绕它构建一套完整的工程化体系,也就是所谓的外围工程。
一般来说,外围工程主要覆盖几个方面:
提示工程(Prompt Engineering):通过设计和编写提示文本,引导模型生成符合特定要求的内容;
知识库系统(RAG):结合外部知识库(如企业文档、FAQ、数据库)进行检索和生成。比如,企业知识问答、IT 技术支持、财务/法律垂类助手等;
模型联网:顾名思义,让模型通过索引网站或搜索引擎上的内容,总结和引用后再输出内容。比如,股市信息摘要、跨境电商价格检索等;
插件系统/工具调用:为模型配置具备特定功能的插件,如搜索、计算、调用API等,使其具备“观察-决策-行动”的能力。背后通常集成多模态输入、外部系统接口、状态管理等能力,是当前智能体(Agent)应用的底座能力之一。
不止这些,还有上下文管理、多模型路由和策略控制、多模态输入和理解支持等,严格来说也都是工程化的一部分。
这套工程放到现在,已然成了AI 产品落地的基本盘,也是策略性工作的重点。尤其是当下的AI产品岗,无论你是服务于B端还是C端场景,几乎都会涉及到这部分职责。
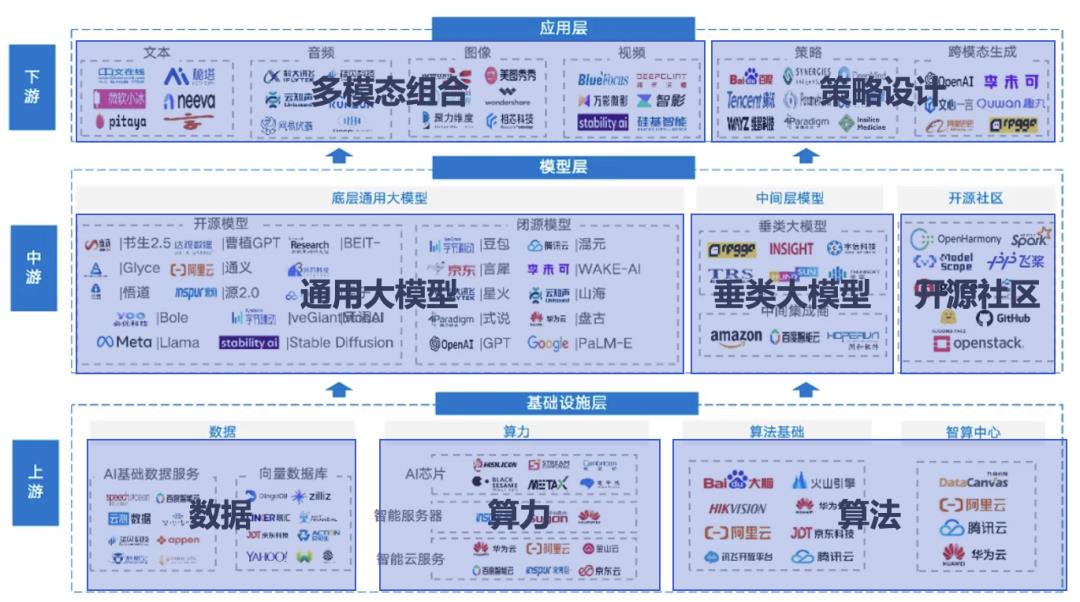
图2:AI 产业上下游的分类
那么,在模型能力调优和外围工程方面,产品经理在其中的职责是什么,和算法、研发之间的分工如何,似乎都不太显性。
简言之,在大模型产品的策略设计中,产品经理不负责“怎么写代码或训练模型”,但必须负责“为什么要做、做哪些、怎么判断做得好”。
基于AI 产品最核心的三种策略手段,我们一个个来说。
| 提示词工程(Prompt Engineering) | |||
| 知识库建设(RAG) | |||
| 微调(SFT/LoRA) |
提示工程是一个成本低、无需编程能力就能做策略调优的工作,产品经理更应该深入到提示工程优化里面去钻研。
把提示词设计流程,用 Figma + 流程图 + 表格做出来,像以前做多轮Bot对话那样设计,即:每一轮都要考虑意图触发 → 指令拆解 → 内容生成 → 格式输出;
建立Prompt组件库,就像你以前建立组件式UI库一样,以便快速复用到不同的Agent或场景中,降低跨部门的协作成本;
建议输出结构时,强约束格式,如 JSON、Markdown、表格等,就像你曾经设计标准返回格式一样。输出结构的格式化,非常便利后续的系统性ab实验,以及对失败case的分类和归因,形成可分析的 Prompt-to-Output Mapping。
本质上,这是将提示词设计上升到“产品工程化”的高度,让提示词不再只是对话玩具,或是一个唬人的心法,而是真正具备工程调用能力的接口设计。
明确哪些问题靠知识库,哪些靠大模型生成,可通过问题类型分类表和意图识别路由策略来实现; 制定知识来源标准(来源渠道、内容标准如准确性、更新时效性、安全性等); 设计知识库的组织结构(FAQ型、实体型、文档型),比如实体型就是基于知识图谱或结构化数据组织的可查询实体,如酒店信息、商品数据等; 制定知识更新机制(静态 or 动态?由谁维护,是否需要人工审核,更新频率等); 设定知识召回策略,即:模型调用知识库的时机和优先级。
举个例子,你正在做一个支持AI 智能客服的产品,模型回答一些标准问题经常答不准或产生幻觉,你判断:
大模型通识能力不够;
提示词的增强效果有限;
需要外挂知识库,采用RAG(Retrieval-Augmented Generation)架构。
要注入什么知识? 知识以什么形式存储? 怎么让模型好用?
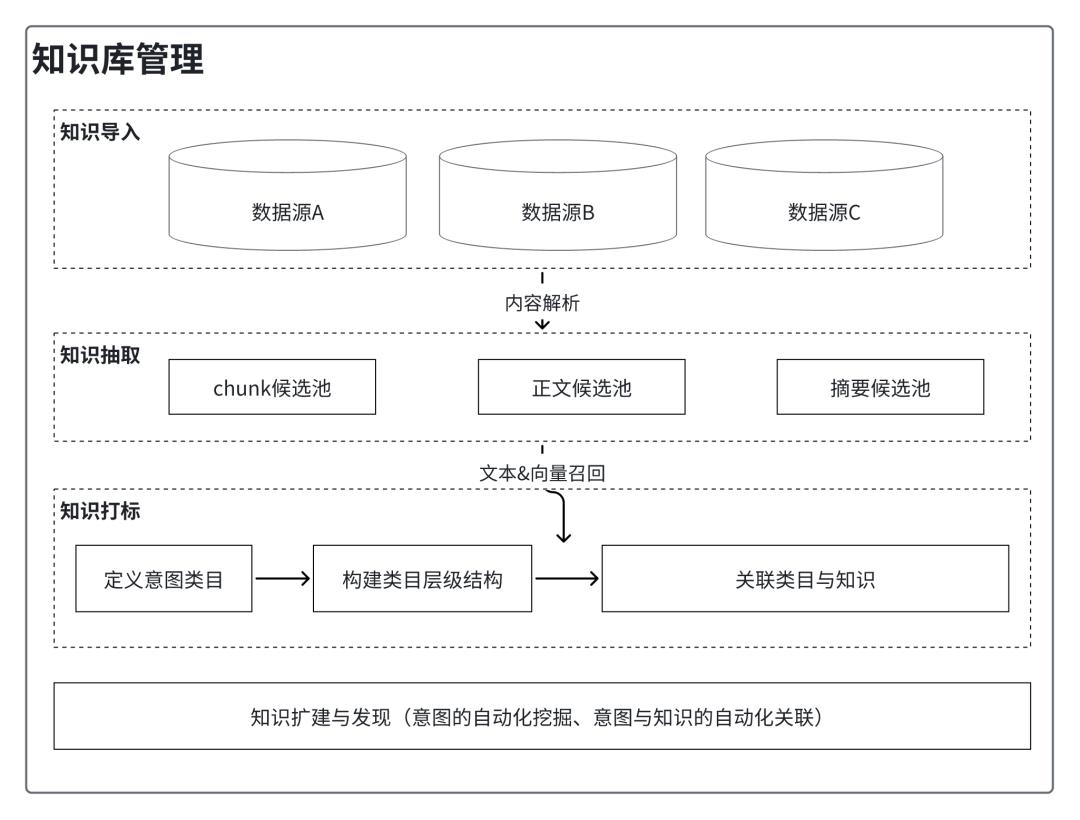
图3:知识库管理
1)知识导入:
明确知识来源,输出《知识内容源清单 & 类型归类表》。为此你要拉通业务团队、客服团队、知识库团队,确认知识结构包括:
2)知识抽取:
产品要负责设计知识颗粒度与分段策略:
分段太粗,可能会导致召回的信息干扰多;
分段太细,容易导致上下文丢失或无法覆盖完整答案。
常见的分段方式有:按文档结构分段,比如每个FAQ一段,每个操作步骤一段;按主题分段,比如按退货、丢件、配送等主题切分;按意图标签组织,比如「物流查询意图」的标准回答集合就是一段。
3)知识召回:
该过程涉及到的环节较多,其中产品经理要注意定义嵌入策略(Embedding),输出知识入库规则,再交给算法或工程团队接入到向量存储平台。
简单来说,Embedding 就是把一句话变成一串能让计算机理解的数字(向量)。当你把知识仓库搭建好,里面有大量的句子和文章,你希望将来别人来提问时,AI能准确找到相关的内容并回答。而 AI 不懂人类的语言,它只能理解数字。因此你需要把文字变成向量,以便后续的向量召回。
注意,你不需要写embedding算法,但你要确定:
分段内容中,哪些字段需要embedding(如正文+标题)
向量库结构:是否需要多模态向量?多个通道?
是否加索引字段用于召回过滤?
其次是RAG调用逻辑的设计,核心目标是:当用户问一句话时,该应用能召回正确的知识段,并组织成有效的prompt,让大模型生成可靠答案。
1)设计检索逻辑,明确检索规则、召回数量和过滤机制,以确保知识的召回率。
3)设计回答可信机制与兜底应对策略。大模型仍可能输出幻觉,因此你要定义:
当召回失败时:输出「抱歉我没找到相关信息」or 其他兜底和引导话术;
当召回信息过多时:提示用户细化或进一步明确问题;
输出结果是否附带“参考信息”字段提升信任感(如“本回答来源于XXX知识文档”)
4)上线后的数据闭环。该过程在所有类型的产品落地时都会多次强调,对知识库而言,你需要重点关注知识的召回率与准确率,同时建立知识内容的版本管理与动态更新机制,确保知识库在实际应用中的持续有效性与业务匹配度。
这不仅是效果评估手段,更是推动知识库持续演进与模型能力迭代的关键机制。
2.3 模型微调
如果说,模型的预训练环节是通过海量的语料让模型学习通用规律,让模型在巨大的图书馆中自学成才,那么微调则是做模型的老师,定义标准答案,负责打磨优质的学生样本出来,对其针对性辅导,以便让模型去学习和模仿。
在预训练环节,参数量和语料的丰富多样几乎直接决定了预训练后模型的智商上限;而在微调环节,样本的质量和多样性决定了模型的专业度和可控性。
举个例子,你做了一个物流客服机器人,泛化模型回答太泛,于是你提出针对「快递物流问题」微调一个专用模型。在微调模型的过程,涉及到具体微调的方法、训练调参的工作,由算法团队支持;但关于微调场景的定义、数据策略和资源的优先级,由产品经理负责。
第一步:明确调优目标,输出能力调优的需求说明书,包含问题类型分析、失败示例、当前能力的评估结果。
你要正面明确以下几个问题:
哪类问题表现差?回答是否稳定?
提示词优化是否有效?
是否值得微调?
第二步:定义微调的数据范围与质量标准,输出《标注任务说明》,包括标签体系、数据格式、案例等,可交给数据团队执行。
第三步:定义微调的策略和能力边界,包括目标、调用逻辑、能力边界和风险点等。
不同之处在于,模型微调的成本更高(研发投入+算力),以至于你必须把评估ROI纳入到每次微调的复盘工作中,去甄别微调带来的满意度提升是否匹配训练+推理的成本投入。
3. 小结
现阶段市面上所谓“AI产品经理”,很多其实只是用过API的“伪AI产品经理”,而真正能从“业务需求→模型能力→场景设计→效果评估与优化”的AI产品经理凤毛麟角。
最后,依旧给自己打个硬广:欢迎扫码或点开原文加入我的知识星球,期待和你有更深入的交流。
下次见!