导读:快速使用大模型搭建自己的知识库

在 AI 大模型普及的当下,很多人习惯用云端模型处理问题,但涉及个人隐私文档、企业敏感数据时,“数据上传” 始终是个隐患。今天就从 “为什么搭” 到 “实际效果”,一步步拆解如何在个人电脑上搭建本地化大模型,让 AI 成为只服务于你的 “专属知识库”。
一、为什么一定要搭本地化大模型?
相比依赖互联网的云端大模型,本地化部署的核心优势集中在 “隐私安全” 和 “回答精准” 两大维度,无论个人还是企业都能直接受益。
二、搭建效果实测:从 “不知所云” 到 “精准应答”
光说优势不够直观,我们用 “查询个人信息” 的实际案例,看本地大模型搭建前后的差异,过程简单到普通人也能看懂。
1、搭建初期:无专属知识的 “空白状态”
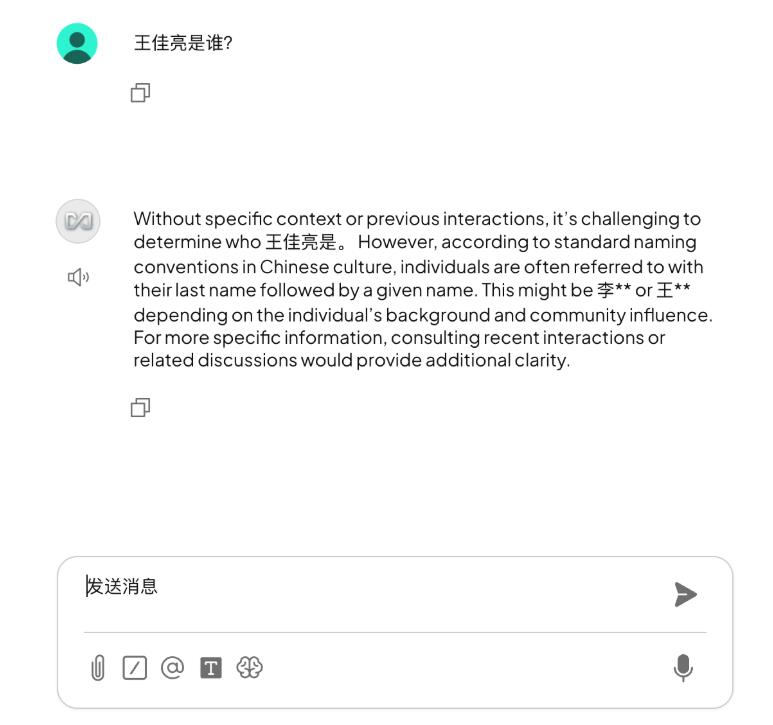
刚搭建好基础模型时,模型仅具备通用知识,未接入任何本地资料。此时提问 “王佳亮是谁?”,模型因无相关信息储备,回答明显偏离实际,甚至出现 “可能是某领域普通从业者,暂无公开详细资料” 这类模糊且无效的内容。
2、接入本地资料:给模型 “喂” 专属文档
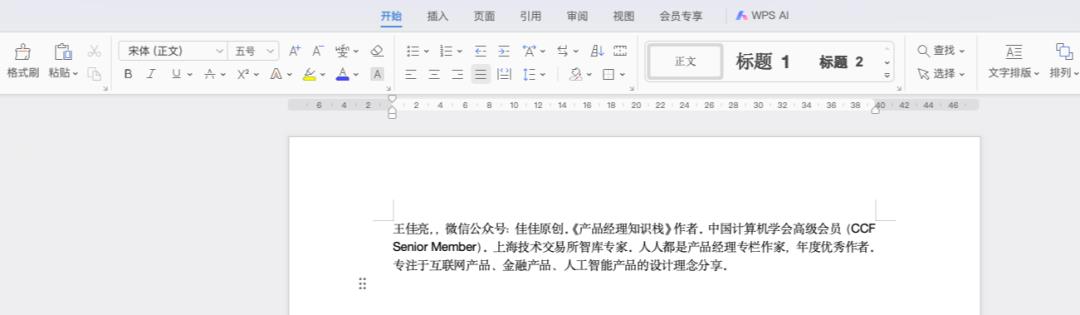
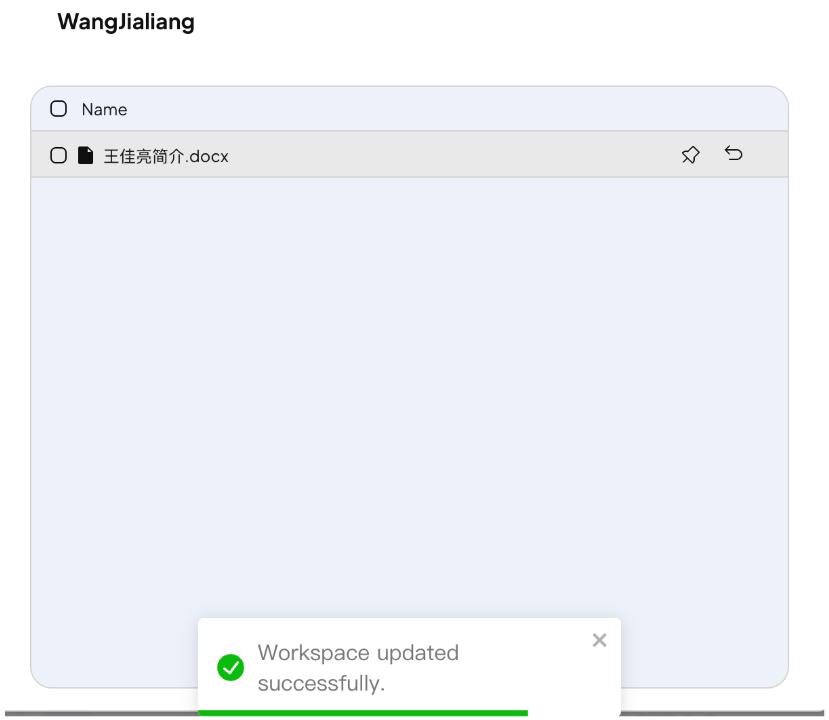
为让模型识别 “王佳亮”,我们先做准备工作:
3、学习后:基于本地资料的精准回答
完成文档学习后,再次提问 “王佳亮是谁?”,模型直接调用刚才学习的《王佳亮简介》内容,准确输出,完全贴合本地文档中的信息,没有任何多余的错误联想。同时也给出了内容引用来源。

到这里,一个能识别你专属信息的本地化大模型就初步搭建完成了 —— 整个过程无需复杂代码,普通人跟着步骤操作就能实现。

三、想动手尝试?进群获取实操指南
如果你也想搭建自己的本地大模型,无论是个人用来看管隐私资料,还是企业用于内部数据处理,都可以加入交流群。群内会分享详细的搭建步骤、适合新手的模型推荐、文档投喂技巧,还能和其他实践者一起解决操作中遇到的问题。
专栏作家
王佳亮,微信公众号:佳佳原创。《产品经理知识栈》作者。中国计算机学会高级会员(CCF Senior Member)。上海技术交易所智库专家。人人都是产品经理专栏作家,年度优秀作者。专注于互联网产品、金融产品、人工智能产品的设计理念分享。
标签 产品经理