有时候,真正让人意外的,不是跌下神坛的速度,而是一个团队面对质疑时的回应方式。
Manus,这家AI Agent圈里曾最受瞩目的创业公司,用四个月时间,完成了从出圈到争议的全流程剧本:3月横空出世,5月宣布完成7500万美元B轮融资,6月被爆裁员、清空微博、迁往新加坡。
很多人第一反应是:这是不是又一个“PPT项目”?是不是用中国工程师打完样、融完资,就转身跑路?就在群情激愤、Manus官方持续沉默的时候,联合创始人季逸超在7月19日凌晨发出了一篇万字技术博客,标题平实,却像是一次迟来的回应——《Context Engineering for AI Agents》。
没有辩解、没有公关,也没有否认任何争议。他选择从最核心的地方讲起:什么是上下文工程,为什么它是智能体发展的真正主线。
读完那篇文章,我感觉:也许Manus没那么完蛋,甚至,它可能是这个行业里,最早认真对待“Agent系统工程化”的团队之一。
01|为什么不自研模型?因为上一家公司输得太惨
这不是Manus第一次创业。联合创始人季逸超在文中提到,上一家公司(Peak Labs)从零训练语义搜索模型,做得很辛苦也很“正统”,但最终败给了GPT-3和Flan-T5:模型刚上线就彻底过时,投入全打水漂。
这一次,团队直接放弃自研底座模型,选择另辟蹊径——在大模型之上做“上下文工程(Context Engineering)”。
简单说,就是用Prompt结构、记忆组织、工具控制等手段,来塑造模型行为、优化推理路径。这种做法不比训练模型容易,甚至可以说更像是一场工程能力与系统设计能力的较量。
他们的逻辑是清晰的:如果模型进步是涨潮,Manus要做的是一艘船,而不是卡在海底的柱子。

02|从“缓存”到“记忆”:智能体的行为不靠模型,而靠上下文
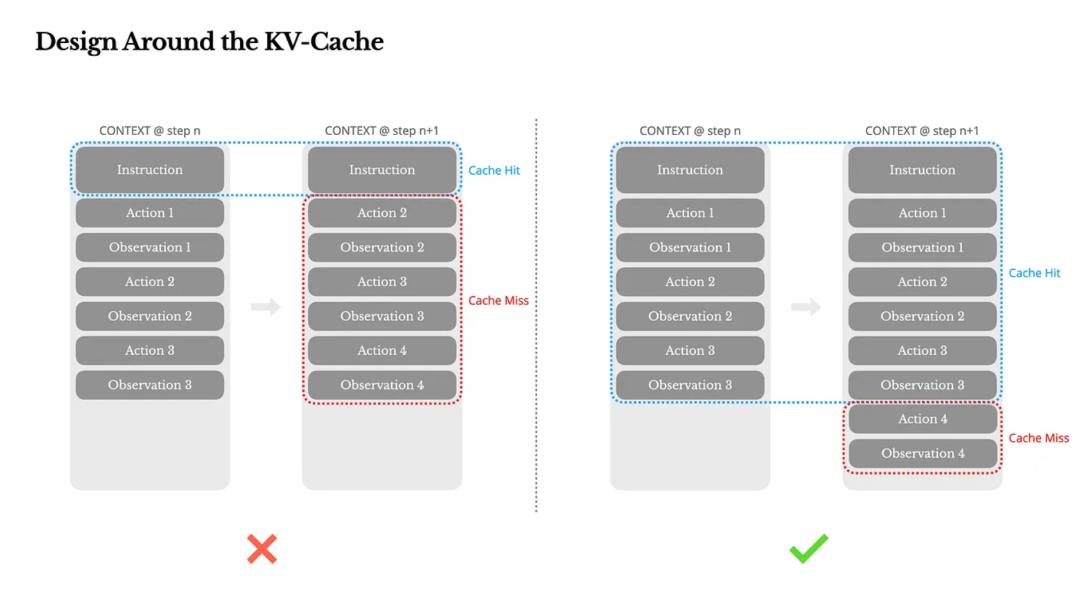
Manus的上下文工程体系,围绕两个关键词展开:KV缓存 和 外部记忆。
KV-Cache 命中率:成本与速度的生命线
智能体和聊天机器人不同,一个Agent平均要执行几十次工具调用,单次输入Token数可能是输出的100倍。
如果上下文结构不稳定,缓存失效,推理成本将指数级上升。以Claude为例,命中缓存每千Token成本$0.30,失效后就是$3 —— 差了整整10倍。
他们的优化手段包括:
上下文“只追加”不修改,避免破坏缓存;
序列化结构稳定化(比如固定JSON键顺序);
不加时间戳,因为哪怕秒级变化也会重写缓存;
引入缓存断点机制,显式标记上下文可重用部分。
这不是优化技巧,而是智能体系统设计的基本功:缓存管理是AI Agent运行效率的“底层红利”。
03|工具爆炸时代:遮蔽比删除更优雅
Manus很早就踩过工具“过载”的坑。
当工具数量从几十个飙升到上百个,Agent不再聪明,反而开始“手忙脚乱”:
经常选错工具;
动作重复;
解码失败;
幻觉调用频发。
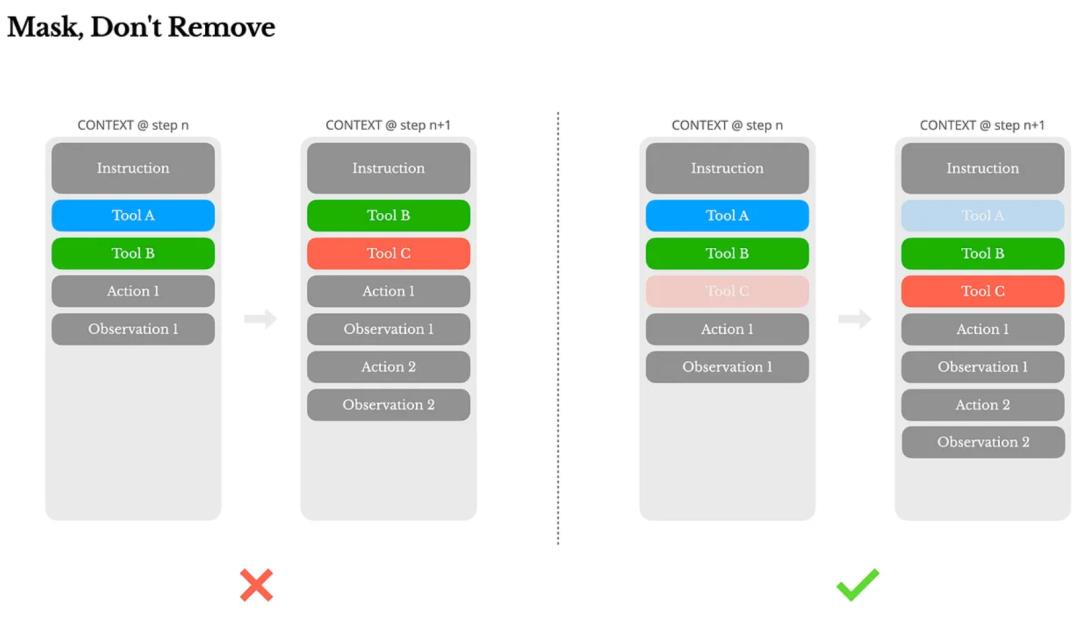
传统的解决方法是“动态加载”——按需增减工具。但这在多轮推理中是灾难,因为工具定义通常写在上下文前部,改一次就导致所有缓存作废。
他们改用遮蔽机制:工具不删,而是在当前状态下屏蔽其Token概率。
更聪明的是,他们使用前缀命名策略(如browser_、shell_),在解码时只开放某一类函数调用,搭配状态机实现控制。这既保留了缓存,又让Agent“知道自己在哪个状态该用什么”。
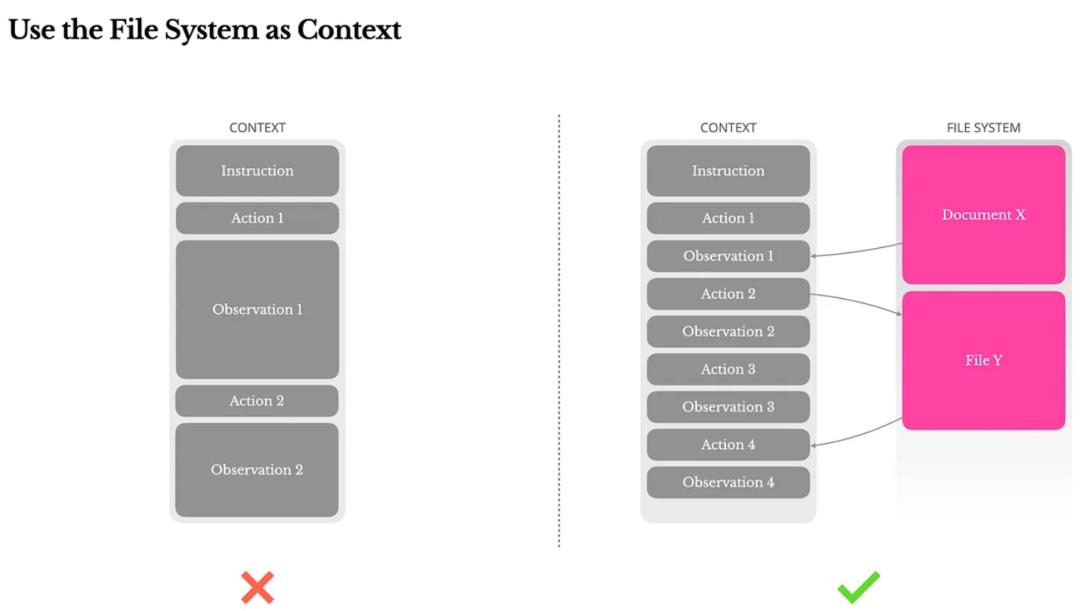
04|把文件系统当记忆:打破128K限制的土办法,可能最有效
大模型上下文再长,也有极限,尤其是Agent任务中:
PDF内容一塞就爆;
网页结构复杂;
多轮观察量巨大;
任务历史难以追踪。
Manus没有选择压缩,而是让Agent自己写入“外部记忆”——文件系统。
模型会在本地记录todo.md、网页缓存、脚本代码等,真正把“环境感知”外包出去。这种机制不仅解决Token限制问题,更是Agent系统长期记忆的实现方式。
你可以理解为“Agent写日记”,只是这些日记是结构化的,并能被它自己随时读回。
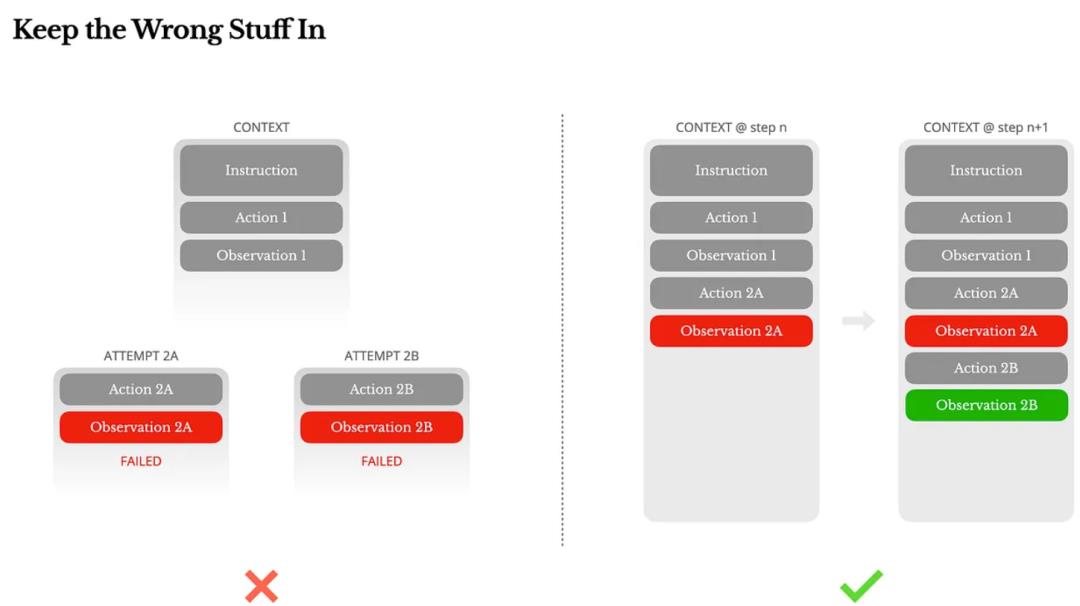
05|错误不能删,因为那是Agent最重要的学习材料
这是我最喜欢的一个点。
我们常常本能地想隐藏AI的错误:删掉失败路径、重新开始任务、或者靠温度参数“洗掉偏差”。
Manus团队反其道而行:保留错误、保留堆栈、保留失败观察。
原因很简单:语言模型通过上下文学习行为。如果你删掉错误,它就永远不知道那是“错的”。而只有当它“看到自己摔倒”,它才会在下一步规避风险。
在LLM主导的Agent系统中,自我修正能力的关键,不是逻辑,而是证据。而这些证据,就藏在那些没被抹去的失败片段中。
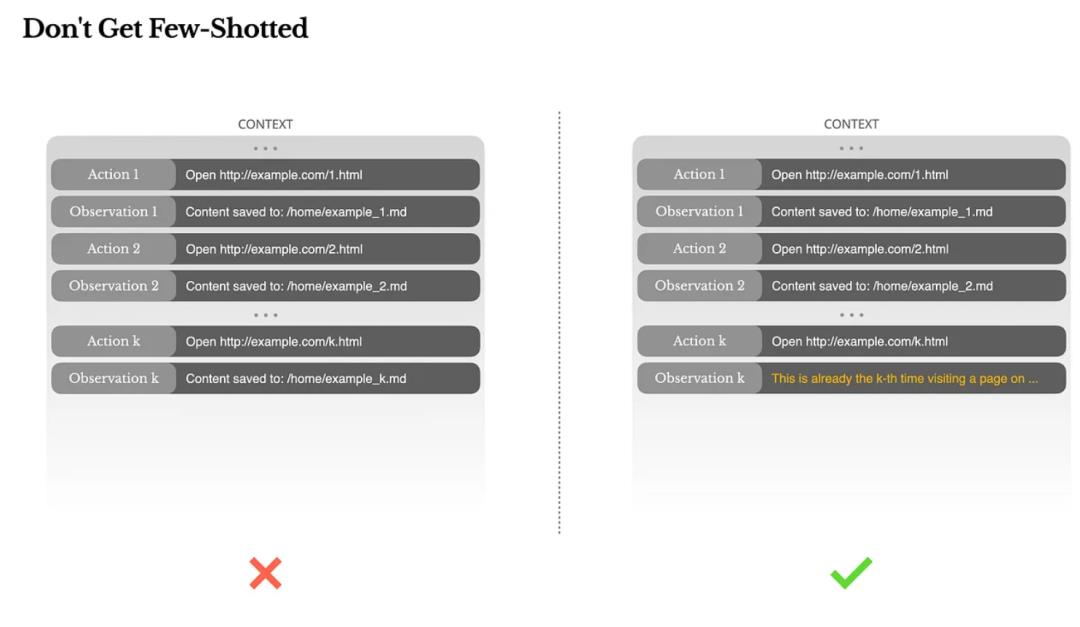
06|不是Few-shot多就好,而是要避免Agent“惯性思维”
Manus最后指出一个大家容易忽略的坑:上下文示例太统一,会导致Agent“路径依赖”。
比如它帮你审简历,前几份都做了类似决策,后面就可能陷入节奏性幻觉,不再真正推理。
他们的应对方式是引入微量扰动:
随机变换表达方式;
同一操作用不同模板;
编码顺序引入轻微噪声。
这些变化不改变内容本质,但可以打破模型注意力的“局部惯性”,让Agent保持对任务的敏感性。
07|上下文工程:不是工程“细节”,而是AI Agent的主干
Manus的复盘,更像一次价值观的宣言:
真正决定Agent是否好用的,不是它用哪个模型、参数多少,而是它有没有记忆、有没有结构、能不能恢复、能不能收敛。
在大厂端到端闭环的生态体系面前,Manus也许注定艰难。但它的这套“上下文塑造行为”的做法,可能是更多创业者能走得通的另一条路。
这篇文章没有洗白Manus所有的争议。但它至少证明,这家公司在Agent系统底层,确实走过了一段不那么浮躁的路径。
如果智能体真是下一代AI应用的未来,那它或许不会靠更大的模型,而会靠一个个用心构建的“上下文”。

??《Context Engineering for AI Agents》:https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus