豆包大模型全类型盘点:一文看懂多模态能力矩阵
导读:豆包大模型以多模态能力为核心,从语言到视觉、语音,覆盖全场景需求,且持续迭代升级,为企业和用户提供更智能的解决方案

豆包大模型涵盖多种类型,能满足不同场景需求,最新推出的豆包大模型 1.6 更是亮点十足。
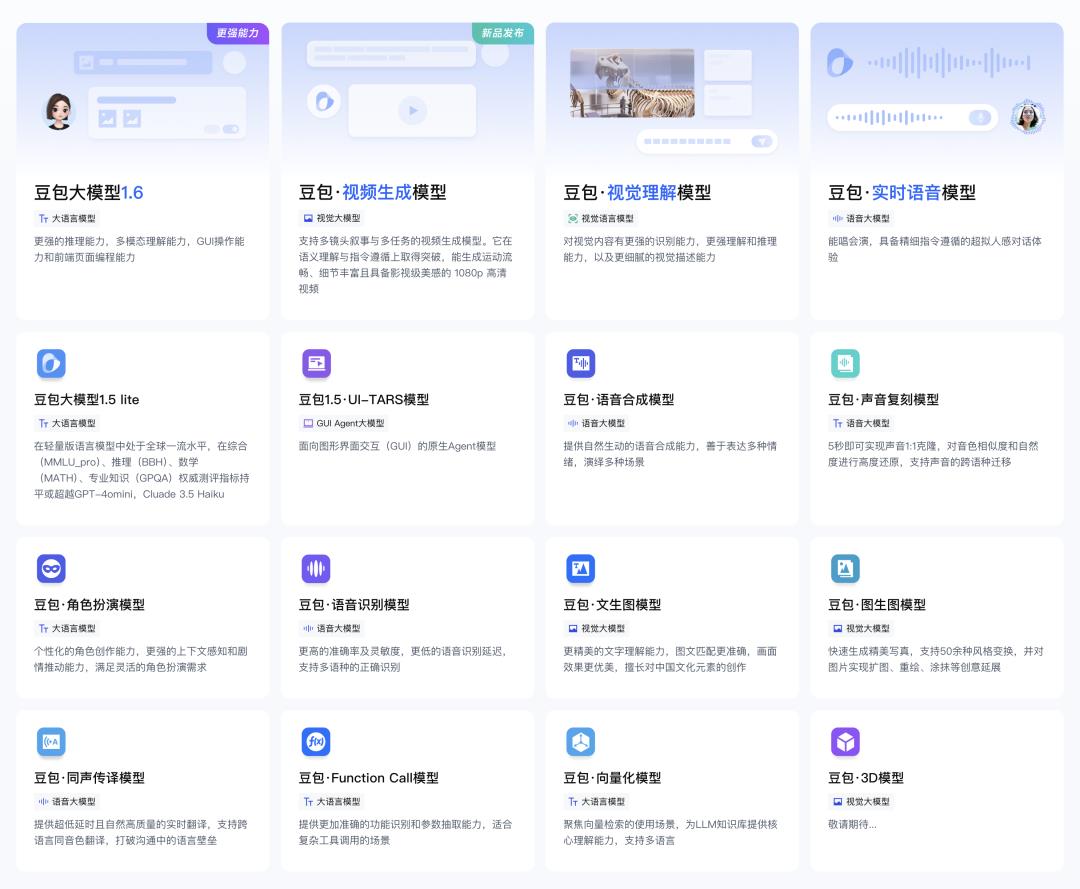
一、大语言模型:智能对话与逻辑核心
- 豆包大模型 1.6
推理能力更强,支持多模态理解、GUI 操作和前端页面编程,长文本处理更出色。 - 豆包大模型 1.5 pro
专业版,支持 256K 长文本,综合能力强。 - 豆包大模型 1.5 lite
轻量版,全球一流水平,多项权威指标超越 GPT-4 omini 等。 - 豆包?角色扮演模型
个性化角色创作,上下文感知强,推动剧情互动。 - 豆包?Function Call 模型
精准识别功能、抽取参数,适配复杂工具调用。 - 豆包?向量化模型
聚焦向量检索,为 LLM 知识库提供核心理解,支持多语言。 - 豆包 1.5?UI-TARS 模型
GUI Agent 大模型,面向图形界面交互的原生 Agent 模型。 - 豆包?通用模型 lite
轻量经济,token 成本低、延迟低。
二、视觉大模型:从图像到视频的创意生成
- 豆包?视频生成模型
支持多镜头叙事,生成 1080p 高清视频,语义理解与指令遵循能力突破。 - 豆包?视觉理解模型
识别、理解、推理视觉内容,描述更细腻。 - 豆包?文生图模型
文字理解精美,擅长中国文化元素创作,图文匹配准确。 - 豆包?图生图模型
生成精美写真,支持 50 + 风格变换,可扩图、重绘、涂抹。 - 豆包?3D 模型
视觉大模型,敬请期待。
三、语音大模型:声音的智能交互革命
- 豆包?实时语音模型
能唱会演,超拟人感对话,精细遵循指令。 - 豆包?语音合成模型
自然生动,表达多种情绪,演绎多场景。 - 豆包?声音复刻模型
5 秒 1:1 克隆声音,高还原度,支持跨语种迁移。 - 豆包?语音识别模型
准确率高、延迟低,支持多语种识别。 - 豆包?同声传译模型
超低延时翻译,跨语言同音色,打破沟通壁垒。
四、其他特色模型:细分场景的专业能力
- 豆包 1.5?深度思考模型
原生多模态,数学、编程推理强,采用 MoE 架构,延迟低。 - 豆包 - Seedance-1.0 系列
视觉大模型,包括 pro、lite-i2v、lite-t2v 等,支持视频生成。 - 豆包 - 视频生成 - Seaweed/Wan2.1-14B
视觉大模型,生成高质量视频。 - 豆包 - 文生图模型 - 智能绘图 / 漫画版
视觉大模型,前者生成精美图像,后者专注漫画创作。 - 向量模型
包括 Doubao-embedding-vision、embedding、embedding-large,聚焦向量检索。
豆包大模型以多模态能力为核心,从语言到视觉、语音,覆盖全场景需求,且持续迭代升级,为企业和用户提供更智能的解决方案。
标签 产品经理