Google 正式推出了 Gemini 3,称其为公司迄今为止最智能的模型。首席执行官 Sundar Pichai 和 Google DeepMind 负责人表示,新系列旨在推动 逻辑推理、多模态理解 和 Agent(智能体)能力 的发展。
Gemini 3 Pro 目前已推出预览版,并将逐步推广至 Google 的全线产品中,包括 Gemini App、AI Studio、Vertex AI 以及 Google 搜索的 AI 模式。这是新一代 Gemini 模型首次在发布当天就可用于搜索。Google 表示,Gemini 3 提供了更强的语境理解和更细致入微的响应。它的回答力求智能、简洁、直截了当,避免使用陈词滥调和奉承之词,转而提供真知灼见。
强大的推理能力将 Gemini 3 推向新的基准高点
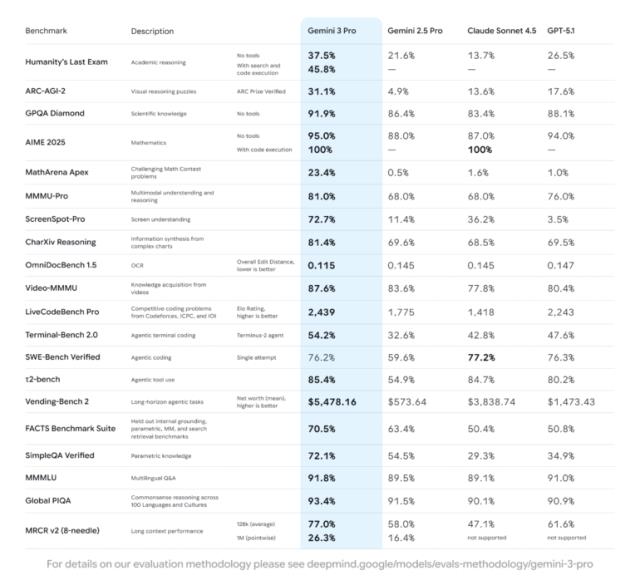
Google 通过一系列基准测试结果,突显了 Gemini 3 Pro 的卓越性能。据报道,它以 1501 的 Elo 分数领跑 LMArena 排名。在测试如“人类终极考试”(Humanity's Last Exam)等博士级推理测试中,Gemini 3 Pro 在不使用工具的情况下达到了 37.5%,在 GPQA Diamond 上达到了 91.9%。这使其超越了 xAI 最近发布的 Grok 4.1。该模型在数学领域也取得了强劲的分数,在 MathArena Apex 上为 23.4%;在多模态理解方面,其在 MMMU-Pro 上达到了 81%。下图是Gemini 3在不同基准上的得分:
根据官方模型卡,Gemini 3 Pro 建立在稀疏混合专家 (sparse mixture-of-experts) Transformer 架构之上。Google 使用了大规模多模态数据集对其进行训练,这些数据包括公开的网络文档、授权数据、合成 AI 数据以及来自 Google 产品和服务的用户数据。该模型的知识截止日期是 2025 年 1 月。
多模态性能成为 Gemini 3 的核心优势
Gemini 3 的显著特征之一是其原生多模态能力,使其能够处理文本、图像、视频和音频。Google 报告称其在 MMMU-Pro 上取得了 81%,在 Video-MMMU 上取得了 87.6% 的顶级成绩。该模型的优势在界面理解方面表现得尤为明显。在 ScreenSpot-Pro 基准测试(用于测试模型定位屏幕元素的能力)中,Gemini 3 Pro 获得了 72.7% 的分数。这使其超越了先前的领导者 Holo2(66.1%),尽管 Holo2 是专为 UI 导航而构建的。它也远远优于竞争对手,如 Claude 4.5 Sonnet(36.2%)和 GPT-5.1(3.5%),相对于 Gemini 2.5 Pro 的 11.4% 实现了重大飞跃。
Google 表示,这些能力开辟了实际应用,例如分析体育录像以改进技术,或生成用于高级可视化的代码。在搜索的 AI 模式中,Gemini 3 可以生成全新的沉浸式视觉布局。而在 Chrome 浏览器中,该模型有望成为一个更可靠的浏览器 Agent。
Deep Think 与 Antigravity 平台
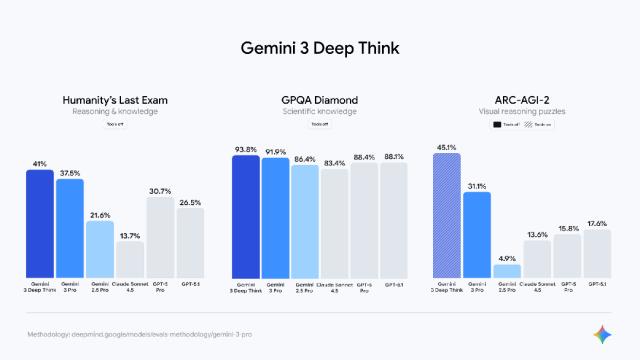
与 Gemini 3 Pro 同时发布的还有 Deep Think 模式,专为更困难的推理任务而设计。在测试中,Deep Think 超越了标准模型本已强劲的结果,在“人类终极考试”中达到 41.0%,在 ARC-AGI-2 基准测试中达到 45.1%。Google 表示,Deep Think 将首先向安全测试人员开放,然后推广给 Google AI Ultra 订阅用户。下图是在这三个基准上的得分:
针对开发者,Google 推出了 Google Antigravity,这是一个以 Agent 为中心的新型开发平台。其目标是将 AI 从一个被动助手转变为 Google 所称的主动合作伙伴。Agent 可以直接访问编辑器、终端和浏览器,并能够自主规划、执行和验证复杂的软件任务。
早期分析表明 Gemini 3 领先于模型竞争
独立评估似乎支持了 Google 的说法。获得 Gemini 3 Pro 早期访问权限的分析公司 Artificial Analysis 表示,该模型目前领跑市场,并在其“Artificial Analysis 智能指数”上的得分比 GPT-5.1 高出三分。下图是“Artificial Analysis 智能指数”排行榜:
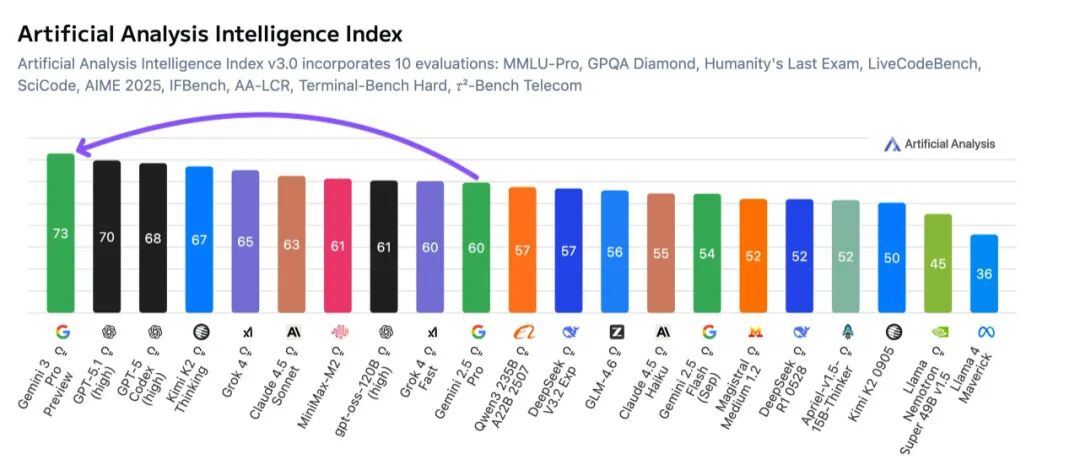
该团队在 X 上报告称,该模型在十个核心基准中的五个上位居第一,包括 GPQA Diamond、MMLU-Pro 和 HLE。他们表示,Gemini 3 Pro 在编码任务、Agent 任务和多模态推理方面特别强大,并在 MMMU-Pro 上取得了最高分。Artificial Analysis 还指出,该模型在衡量知识和幻觉的 AA-Omniscience 基准上的结果表明其模型规模相对较大,与 Anthropic 的 Opus 4.1 相似。
性能提升伴随着更高的运营成本
Artificial Analysis 表示,Gemini 3 Pro 的顶级性能也带来了更高的成本。对于低于 200,000 token 的上下文,定价为每百万输入 token 2 美元,每百万输出 token 12 美元。这比 Gemini 2.5 Pro(输入 1.25 美元,输出 10 美元)和定价相同的 GPT-5.1 更贵。
不过,Google 对 Gemini 3 Pro 的定价仍低于其他高端模型,例如 Claude 4.5 Sonnet(输入 3 美元,输出 15 美元)和 Grok 4.1(输入 3 美元,输出 15 美元)。它也比最昂贵的选项便宜得多,包括 Claude 4.1 Opus(输入 15 美元,输出 75 美元)和 GPT-5 Pro(输入 15 美元,输出 120 美元)。
对于超过 200,000 token 的更大上下文,Gemini 3 Pro 的输入价格跃升至 4 美元,输出价格跃升至 18 美元。预计 Deep Think 的成本会更高。
该模型的 token 效率 高于 Gemini 2.5 Pro,但更高的费率仍然使得运行 Artificial Analysis 基准指数的成本比旧模型增加了 12%。分析师指出,Gemini 3 Pro 通过速度进行弥补,每秒可生成多达 128 个输出 token,这比 GPT-5.1 等模型更快。
可靠性分析显示出喜忧参半的局面。Gemini 3 Pro 在知识测试中达到了 88% 的准确率,是报告的最高分数之一,但 Artificial Analysis 也观察到其幻觉率高于竞争对手模型。Google 在模型卡中没有给出具体的幻觉指标,仅将其描述为基础模型的一个已知限制。
感谢阅读,您的分享和订阅是对我最大的鼓励和支持: