ChatGPT 现已具备自主处理复杂任务的能力
ChatGPT 现已能够独立处理从网络搜索到制作演示文稿等各种复杂任务。这项新功能整合了早期的研究成果,并赋予了聊天机器人访问虚拟计算机环境的能力。
据 OpenAI 称,ChatGPT 现在通过主动从所谓的“智能体能力”工具箱中选择并直接在其虚拟计算机中运行这些能力来完成任务。这意味着用户可以要求它执行诸如规划和购买早餐菜单、分析竞争对手并创建演示文稿,或者根据当前新闻整理日历条目等任务。
“ChatGPT 智能体”旨在浏览网站、筛选结果、在需要时提示登录、执行代码、运行分析以及创建可编辑文档,如演示文稿或电子表格。
统一智能体系统:核心升级
此次更新的核心是 OpenAI 称之为“统一智能体系统”的东西。该公司表示,它将早期工具(如用于自主使用浏览器的“Operator”和用于信息检索和合成的“Deep Research”)的优势与 ChatGPT 的智能融合在一起。此前,这些系统是独立工作的:Operator 无法分析数据,Deep Research 无法与网站交互。现在,它们的整合开辟了新的用例。
复杂工作流的工具箱
ChatGPT 智能体内置了多种工具:用于图形界面的可视化浏览器、用于简单网络查询的文本浏览器、计算机终端以及直接 API 访问。人工智能应该会自动选择最适合任务的工具。通过连接器,该智能体还可以访问 Gmail 或 Github 等应用程序。
所有这些都在云端的一个虚拟计算机环境中进行,该环境可以跟踪不同工具之间的上下文。OpenAI 强调用户始终保持控制。智能体在执行任何有后果的操作之前都会请求许可,用户可以随时中断、接管浏览器或停止任务。如果智能体需要更多详细信息才能完成目标,它也会主动询问。
性能基准测试表现卓越
OpenAI 表示,驱动该智能体的底层模型在多项基准测试中取得了新的最先进成果。在测试人工智能专家级问题的“Humanity's Last Exam”(HLE)中,该模型取得了 41.6 的新高分。对于严苛的数学基准测试“FrontierMath”,它取得了 27.4% 的准确率。
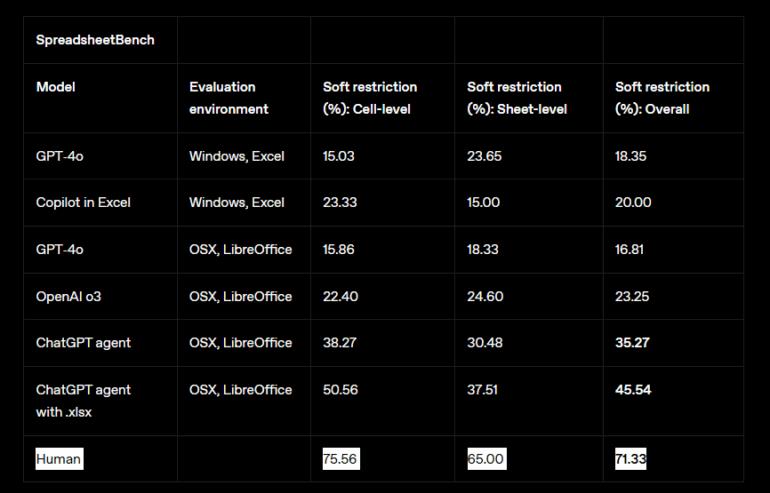
在衡量数据科学任务表现的“DSBench”中,OpenAI 声称 ChatGPT 智能体的性能显著优于人类。在测试电子表格处理的“SpreadsheetBench”中,该智能体得分为 45.5%,而 Excel 中的 Copilot 得分为 20%。尽管如此,在这些任务中人类仍然表现更优。
对于网络导航,“BrowseComp”基准测试显示了 68.9% 的新最先进结果,比 Deep Research 提高了 17.4 个百分点。
发布范围和新功能
新智能体目前正在向 Pro、Plus 和 Team 用户推出,Enterprise 和 Education 客户将在未来几周内陆续获得。欧洲经济区和瑞士的用户仍在准备中。演示文稿制作功能处于测试阶段,OpenAI 表示结果可能仍不尽完善。
Pro 用户每月可获得 400 条消息,而 Plus 和 Team 用户每月可获得 40 条。首次可以购买额外消息。
OpenAI 应对新风险和安全问题
允许 ChatGPT 在网络上执行操作引入了新的风险,尤其是在用户数据方面。OpenAI 表示总体风险状况更高。该公司正致力于防范“提示注入”,即攻击者试图通过网页中的隐藏指令来操纵智能体。
OpenAI 的对策包括训练模型识别此类攻击、监控系统,以及在任何高影响操作之前要求明确的用户确认。一些关键任务,例如发送电子邮件,需要额外的“观察模式”进行监控,而银行转账等高风险操作则默认被阻止。
由于这些新能力,OpenAI 根据其准备框架将该智能体归类为具有“高生物和化学能力”,并已启动了额外的安全措施。该公司表示,这是其为 ChatGPT 实施的最全面的安全架构。措施包括详细的威胁模型、防止在生物和化学领域滥用的特殊培训、使用分类器和推理监视器进行持续监控,以及针对可疑活动的明确升级流程。
在开发过程中,OpenAI 与外部生物安全专家、安全机构和研究人员合作审查和验证保护措施。生物专业人员的红队演练旨在测试现实场景中的防御能力。OpenAI 表示,它采用了多层安全方法,涉及外部合作伙伴以尽早发现新风险。该公司还启动了一项漏洞赏金计划,以帮助发现现实世界中的风险。